시계열 데이터 EDA [ACF, PACF]
시계열 데이터 EDA [ACF, PACF]
1. 시각화를 통한 시계열 데이터 탐색
1
2
3
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
1
eustockmarkets = pd.read_csv('~/aiffel/time_series_basic/EuStockMarkets.csv')
1
eustockmarkets.head()
| DAX | SMI | CAC | FTSE | |
|---|---|---|---|---|
| 0 | 1613.63 | 1688.5 | 1750.5 | 2460.2 |
| 1 | 1606.51 | 1678.6 | 1718.0 | 2448.2 |
| 2 | 1621.04 | 1684.1 | 1708.1 | 2470.4 |
| 3 | 1618.16 | 1686.6 | 1723.1 | 2484.7 |
| 4 | 1610.61 | 1671.6 | 1714.3 | 2466.8 |
1-1. 선도표, 라인 플롯(Line plot)
1
2
3
4
5
6
7
8
9
10
fig, axes = plt.subplots(4, 1, figsize=(10, 8), sharex=True)
markets = eustockmarkets.columns
for i, market in enumerate(markets):
axes[i].plot(eustockmarkets[market])
axes[i].set_title(market)
axes[i].grid(True)
plt.tight_layout()
plt.show()
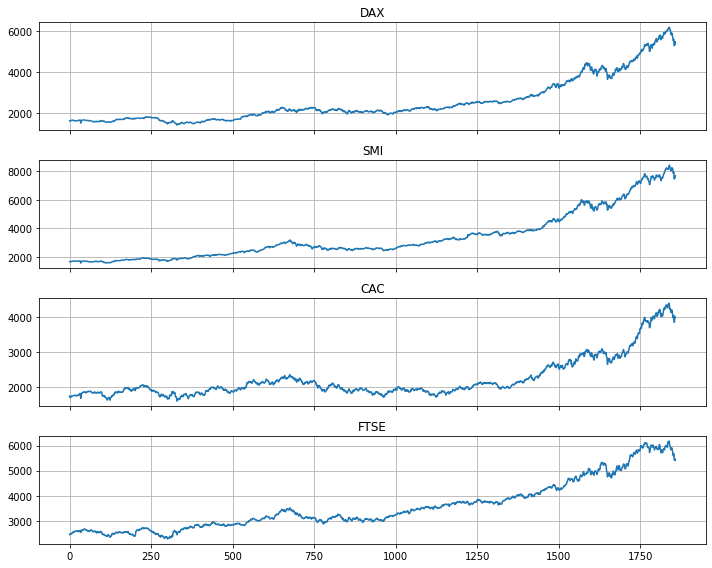
- 기본적으로 시계열을 파악할 때 활용되는 Plot
- 시계열의 형태와 변화를 쉽게 포착할 수 있음.
1-2. 히스토그램 (Histogram)
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
# 필요한 컬럼 추출
smi = eustockmarkets["SMI"]
# 히스토그램 그리기
fig, axes = plt.subplots(1, 2, figsize=(12, 5))
# 왼쪽: 30차 차분
smi_diff = smi.diff(30).dropna()
axes[0].hist(smi_diff, bins=30, edgecolor='black')
axes[0].set_title('Histogram of 30-lag Differenced SMI')
axes[0].set_xlabel('diff(SMI, 30)')
axes[0].set_ylabel('Frequency')
# 오른쪽: 원본 SMI
axes[1].hist(smi, bins=30, edgecolor='black')
axes[1].set_title('Histogram of SMI')
axes[1].set_xlabel('SMI')
axes[1].set_ylabel('Frequency')
plt.tight_layout()
plt.show()
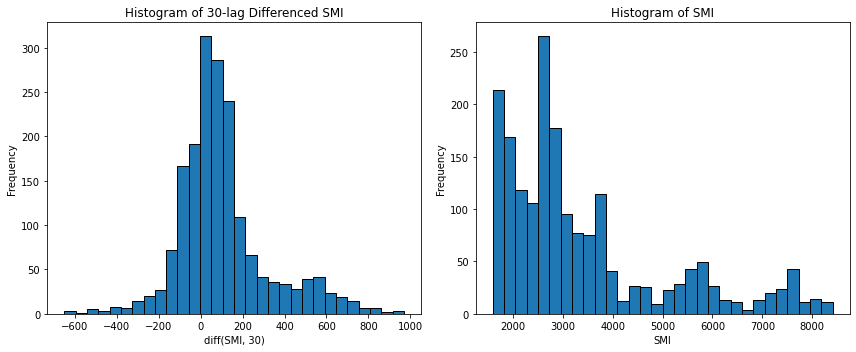
- 데이터의 분포를 판단할 때 사용한다.
- 일반적으로 시계열 데이터는 1차 차분(변화량)에 대해 히스토그램을 그리면 특정한 분포를 볼 수 있다.
1-3. 산점도(Scattor plot)
1
2
3
4
5
6
7
8
plt.figure(figsize=(6, 6))
plt.scatter(eustockmarkets["SMI"], eustockmarkets["DAX"], facecolors='none', edgecolors='black', s=20)
plt.xlabel('EuStockMarkets[, "SMI"]')
plt.ylabel('EuStockMarkets[, "DAX"]')
plt.title('Scatter plot of DAX vs. SMI')
plt.grid(True)
plt.tight_layout()
plt.show()
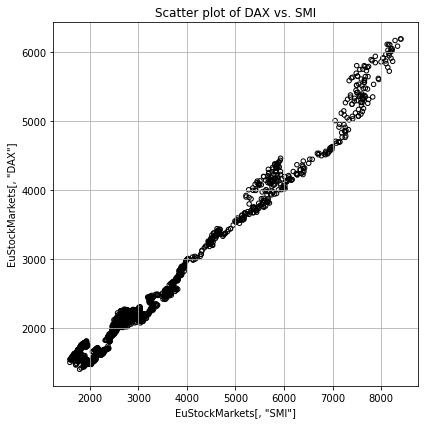
- 산점도의 경우 두 시계열의 관계에 대한 유의미한 정보를 확인할 수 있다.
- 이 경우에도 데이터를 차분함으로써 새로운 의미를 찾아볼 수 있다.
같은 Plot도 무엇을 축으로 삼느냐에 따라 다른 의미를 추출해낼 수 있다.
2. 시계열에 특화된 EDA 방법
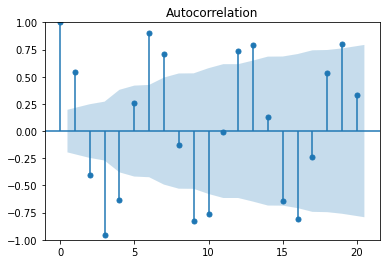
2-1. ACF(AutoCorrelation Function) Plot
- 자기 상관: 시계열 데이터에서 일정 간격이 있는 값들 사이의 상관관계를 의미
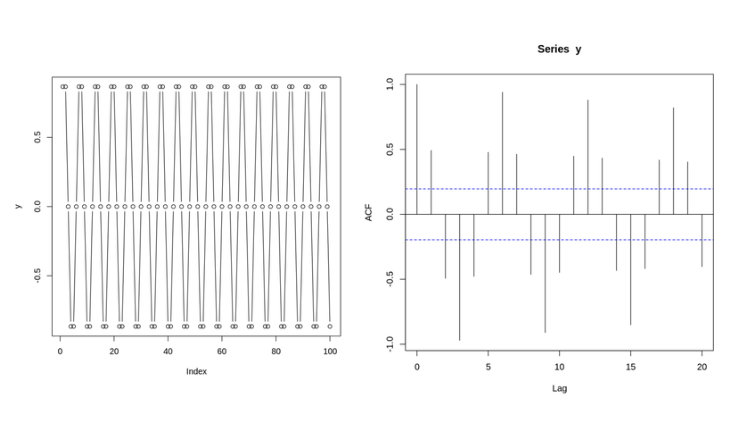
- 사인함수(왼쪽)와 사인함수의 ACF Plot(오른쪽)
- 임계값이 파란색으로 나타나있다.
- 임계값을 넘으면 해당 시차 (lag) 에서의 자기상관이 통계적으로 유의미하다는 뜻
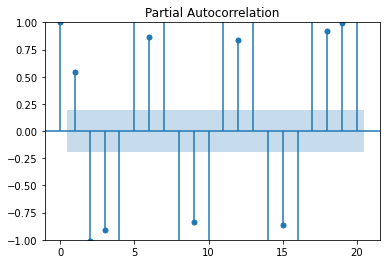
2-2. PACF(Partial AutoCorrelation Function) Plot
- 편자기상관: 자신에 대한 그 시차의 편상관을 의미함.
두 시점사이의 전체 상관관계에서 그 사이 다른 시점의 조건부 상관관계를 뺀 것
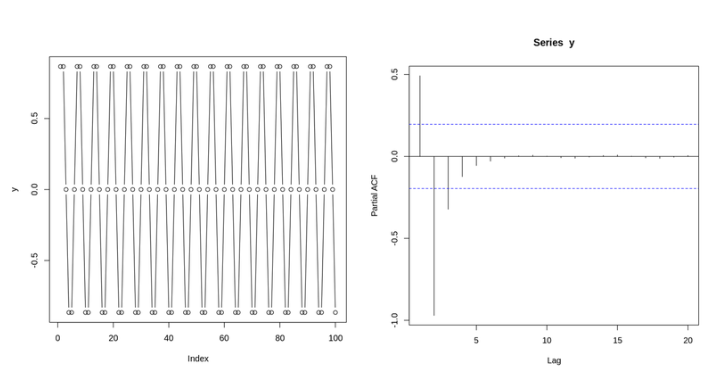
- 사인함수(왼쪽)와 사인함수의 PACF Plot(오른쪽)
- ACF에서 불필요한 중복 관계가 제거된 것을 볼 수 있다.
2-3. ACF와 PACF의 의미적 차이
- ACF의 경우 두 시점간의 상관관계를 계산할 때 두 시점 사이의 모든 lag에 대한 정보가 들어간다.
- PACF는 오로지 두 시점만의 상관관계만을 계산한다. (다른 lag는 조건부 상관관계로 제거)
2-4. 시계열 데이터 EDA
1
2
3
4
5
6
7
8
# 직접 사인함수를 만들고 ACF와 PACF에 적용하여 시각화된 결과를 확인하자.
import numpy as np
import matplotlib.pyplot as plt
from statsmodels.graphics.tsaplots import plot_acf, plot_pacf # statsmodels은 통계 모델 추정, 통계 결과, 통계 데이터 탐색을 지원하는 python 모듈입니다.
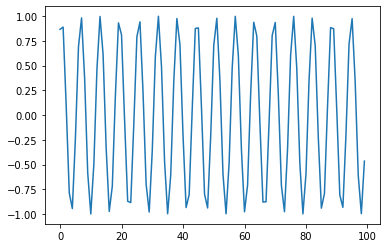
x = np.array(range(100)) # 0~99까지 생성
y = np.sin(x + np.pi/3) # X에 0부터 99까지 할당하고, 이를 numpy.sin에 통과시키면 사인 함수 값이 도출됩니다.
1
2
plt.plot(y)
plt.show()
1
2
plot_acf(y)
plt.show()
1
2
plot_pacf(y)
plt.show()
1
2
/opt/conda/lib/python3.9/site-packages/statsmodels/graphics/tsaplots.py:348: FutureWarning: The default method 'yw' can produce PACF values outside of the [-1,1] interval. After 0.13, the default will change tounadjusted Yule-Walker ('ywm'). You can use this method now by setting method='ywm'.
warnings.warn(
2-5. Non-stationary 데이터의 ACF 및 PACF
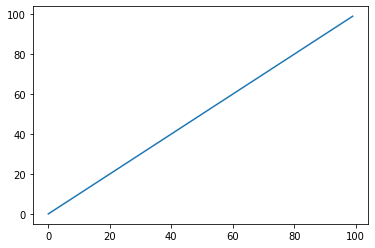
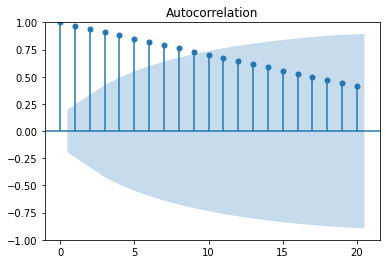
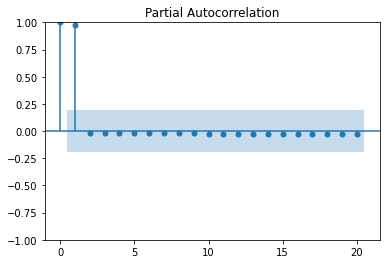
1부터 100까지 선형적으로 증가하는 데이터의 ACF plot과 PACF plot이다.
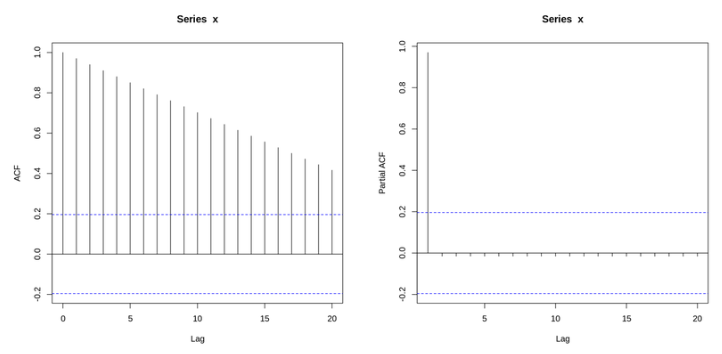
- 크게 유의미한 정보를 보여주지 못함
- 값들은 단순히 균등하게 증가하는 것이기 때문에, PACF와 ACF로부터도 크게 유용한 정보를 얻을 수 없다.
1
2
plt.plot(x)
plt.show()
1
2
plot_acf(x)
plt.show()
1
2
plot_pacf(x)
plt.show()
1
2
/opt/conda/lib/python3.9/site-packages/statsmodels/graphics/tsaplots.py:348: FutureWarning: The default method 'yw' can produce PACF values outside of the [-1,1] interval. After 0.13, the default will change tounadjusted Yule-Walker ('ywm'). You can use this method now by setting method='ywm'.
warnings.warn(
시계열 EDA에서 체크해야할 가장 중요한 위험은 ‘허위 상관’ (spurious correlation)이며 이것은 두 개 이상의 변수가 통계적 상관은 있지만 인과관계가 없는 관계를 말한다.
본 문서는 Aiffel LMS 강의 내용을 바탕으로 개인 학습 목적으로 정리하였습니다.
상업적 이용 목적은 없으며, 원 저작권은 Aiffel에 있습니다.
This post is licensed under CC BY 4.0 by the author.