1. 미래 예측
시계열: 시간 순서대로 발생한 데이터의 수열
- 미래의 데이터를 예측하려면, 두 가지의 전제가 필요하다.
- 과거의 데이터에 일정한 패턴이 발견된다.
- 과거의 패턴은 미래에도 동일하게 반복될 것이다.
위 두 가지 전제를 한 문장으로 줄이면 다음과 같다.
정상성(Stationary) 데이터에 대해서만 미래 예측이 가능하다
- 정상성이라는것은 시계열 데이터의 통계적 특성이 변하지 않는 것
2. Stationary한 시계열 데이터
정상성에서 말하는 시간이 흘러도 일정해야하는 통계적 특성은 다음 세 가지이다.
- 평균
- 분산
- 공분산
그런데 위 통계량을 흐르는 시간 속에서 의미있게 가져가려면, 구간에 따른 통계치를 봐야한다. 즉, 위 세 가지 대신 다음 세 가지 통계치가 일정해야 한다.
- 이동평균
- 이동표준편차
- 자기공분산
개념 정리
직전 5년 치 판매량 X(t-4), X(t-3), X(t-2), X(t-1), X(t)를 가지고 X(t+1)이 얼마일지 예측해보자.
3. 시계열 데이터 사례 분석
3-1. 시계열(Time Series) 생성
1
2
3
4
5
6
7
| import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import os
import warnings
warnings.filterwarnings('ignore')
|
1
2
3
| df = pd.read_csv('~/aiffel/stock_prediction/data/daily-min-temperatures.csv' )
print(type(df))
df.head()
|
1
| <class 'pandas.core.frame.DataFrame'>
|
| Date | Temp |
|---|
| 0 | 1981-01-01 | 20.7 |
|---|
| 1 | 1981-01-02 | 17.9 |
|---|
| 2 | 1981-01-03 | 18.8 |
|---|
| 3 | 1981-01-04 | 14.6 |
|---|
| 4 | 1981-01-05 | 15.8 |
|---|
- 시계열이라는 것도 결국 시간 컬럼을 index로 하는 series로 표현된다.
- 우리가 읽어 들인 데이터 파일은 df 형태로 변한됨.
1
2
3
4
| # df에서 date컬럼을 index로 삼아 시계열을 생성해보자.
df = pd.read_csv('~/aiffel/stock_prediction/data/daily-min-temperatures.csv', index_col='Date', parse_dates=True)
print(type(df))
df.head()
|
1
| <class 'pandas.core.frame.DataFrame'>
|
| Temp |
|---|
| Date | |
|---|
| 1981-01-01 | 20.7 |
|---|
| 1981-01-02 | 17.9 |
|---|
| 1981-01-03 | 18.8 |
|---|
| 1981-01-04 | 14.6 |
|---|
| 1981-01-05 | 15.8 |
|---|
1
2
3
4
| # 시간 컬럼이 index가 되었지만 여전히 type은 DataFrame으로 나온다.
ts1= df['Temp'] # 데이터 확인용
print(type(ts1))
ts1.head()
|
1
2
3
4
5
6
7
8
9
10
11
12
13
| <class 'pandas.core.series.Series'>
Date
1981-01-01 20.7
1981-01-02 17.9
1981-01-03 18.8
1981-01-04 14.6
1981-01-05 15.8
Name: Temp, dtype: float64
|
- 명확하게 Series 객체를 가지고 진행하자.
3-2. 시계열 정상성 분석
이제 시계열이 준비되었으므로, 시각화를 통해 정상성(Stationarity) 여부를 확인해보자.
1
2
3
4
| from matplotlib.pylab import rcParams
rcParams['figure.figsize'] = 13, 6
plt.plot(ts1)
|
1
| [<matplotlib.lines.Line2D at 0x7409d5495bb0>]
|
- 분석에 들어가기 전에 잊지 말고 결측치 유무 확인을 하자.
1
| Series([], Name: Temp, dtype: float64)
|
- 다행히 이 데이터에는 결측치가 없다.
- 만약 있다면 두 가지 방법으로 결측치를 처리할 수 있다.
- 결측치가 있는 데이터를 모두 삭제 (drop)
- 결측치 양옆의 값들을 이용해서 적절히 보간(interpolate)하여 대입
- ex) 2와 4 사이 데이터가 NaN이라면 이 값을 3으로 채우는 방식
1
2
3
4
5
6
7
8
9
| # 이번 경우라면 시간을 index로 가지는 시계열 데이터이므로 삭제하는 것보다는 보간하는 방법을 선택하자.
# 결측치가 있다면 이를 보간
# 보간 기준은 time
ts1=ts1.interpolate(method='time')
print(ts1[ts1.isna()])
plt.plot(ts1)
|
1
2
3
4
5
6
7
| Series([], Name: Temp, dtype: float64)
[<matplotlib.lines.Line2D at 0x7409d3343d00>]
|
- 직관적으로 봤을 때 시간 추이에 따라 일정한 평균, 분산, 자기공분산의 패턴이 나타나는 것 같다.
- 시계열 데이터의 통계적 특성을 좀 더 명료하게 시각화해보자.
구간 통계치(Rolling Staistics)
- 현재 타임 스텝부터 window에 주어진 타임 스텝 이전 사이
- window : 특정 개수 (d)
- 구간의 평균(이동평균)
- 구간의 표준편차(이동표준편차)를
- 원본 시계열과 함께 시각화해보면 좀 더 뚜렷한 경향성을 확인할 수 있다.
1
2
3
4
5
6
7
8
9
10
11
12
| def plot_rolling_statistics(timeseries, window=12):
rolmean = timeseries.rolling(window=window).mean() # 이동평균 시계열
rolstd = timeseries.rolling(window=window).std() # 이동표준편차 시계열
# 원본시계열, 이동평균, 이동표준편차를 plot으로 시각화해 본다.
orig = plt.plot(timeseries, color='blue',label='Original')
mean = plt.plot(rolmean, color='red', label='Rolling Mean')
std = plt.plot(rolstd, color='black', label='Rolling Std')
plt.legend(loc='best')
plt.title('Rolling Mean & Standard Deviation')
plt.show(block=False)
|
1
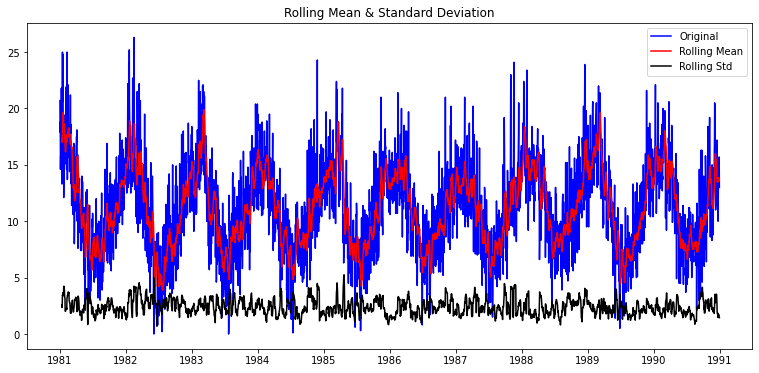
| plot_rolling_statistics(ts1, window=12)
|
window=12 (12개월 기준)
- 목적: 짧은 구간(예: 1년 중 월별 수준)의 추세와 분산 확인.
- 해석:
Rolling Mean (빨간색): 원래 시계열보다 훨씬 부드럽게 보인다.- 평균값이 계절성을 따라 주기적으로 변한다는 걸 보여줌.
Rolling Std (검정색): 대체로 일정한 수준을 유지, 즉 분산은 시간에 따라 큰 변화가 없음.
- 결과: 계절적 요소가 강하다는 걸 시사함. (연 단위 주기 반복)
1
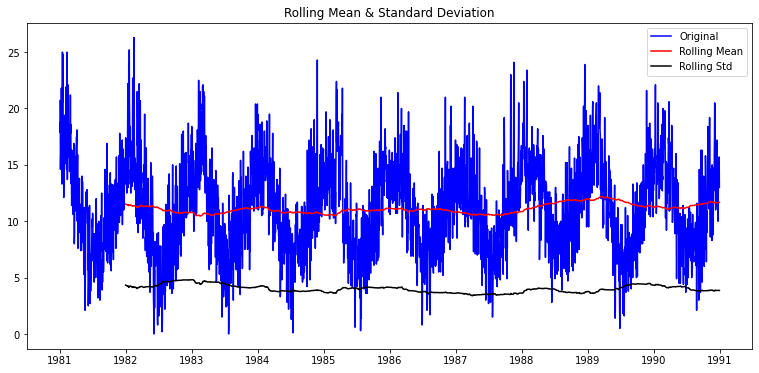
| plot_rolling_statistics(ts1, window=365)
|
window=365 (1년 단위)
- 목적: 장기 추세와 분산 안정성 확인.
- 해석:
Rolling Mean은 약간의 상승 또는 하강 추세를 보여줍니다- 이는 시계열이 추세성(trend) 을 가질 수 있다는 뜻.
Rolling Std도 비교적 일정
- 이 시계열 데이터가 안정적이라고 명확하게 결론짓기는 어렵다. (시각화만 봤을 때는 그렇게 말할 수도 있음)
- 명확하게 단정 지으려면 좀 더 통계적인 접근이 필요하다.
3-3. 다른 데이터에 대해서도 비교해보자.
- 이번에는 International airline passengers 데이터셋
- 월별 항공 승객 수(천명 단위)의 시계열 데이터인데 기온 변화 데이터셋과는 좀 다른 패턴이 나타나지 않을까? 위와 동일한 방법으로 분석해 보겠습니다.
1
2
3
4
| dataset_filepath = os.getenv('HOME')+'/aiffel/stock_prediction/data/airline-passengers.csv'
df = pd.read_csv(dataset_filepath, index_col='Month', parse_dates=True).fillna(0)
print(type(df))
df.head()
|
1
| <class 'pandas.core.frame.DataFrame'>
|
| Passengers |
|---|
| Month | |
|---|
| 1949-01-01 | 112 |
|---|
| 1949-02-01 | 118 |
|---|
| 1949-03-01 | 132 |
|---|
| 1949-04-01 | 129 |
|---|
| 1949-05-01 | 121 |
|---|
1
2
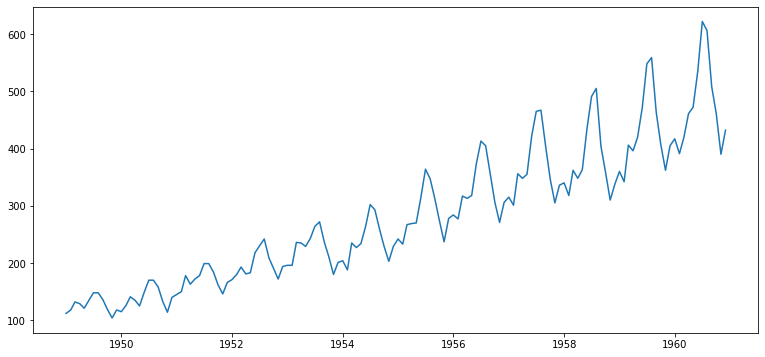
| ts2 = df['Passengers']
plt.plot(ts2)
|
1
| [<matplotlib.lines.Line2D at 0x7409d17eca30>]
|
- 시간의 추이에 따라 시계열의 평균과 분산이 지속적으로 커지는 패턴을 보임.
- rolliing statistics를 추가해서 시각화하자.
1
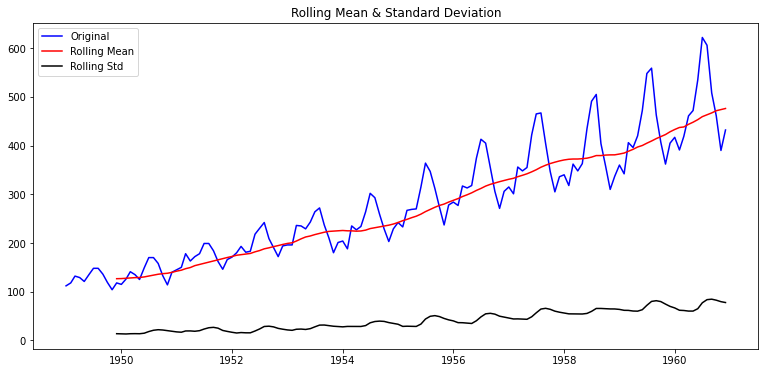
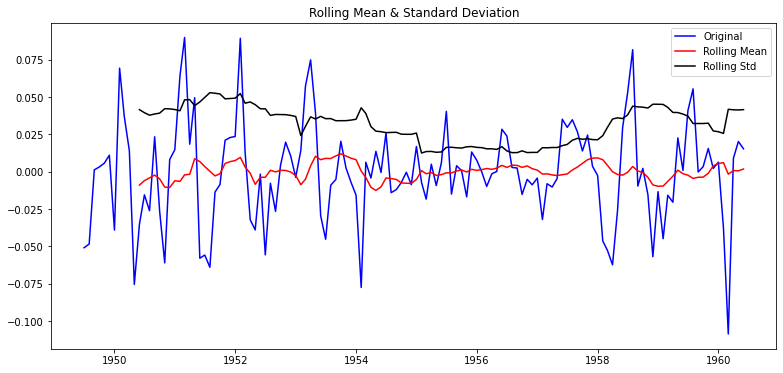
| plot_rolling_statistics(ts2, window=12)
|
- 이 시계열 데이터는 적어도 안정적이진 않다고 정성적인 결론을 내려볼 수 있을 것 같다.
- 불정성적(Non-Stationary) 시계열 데이터에 대한 시계열 분석 기법을 다뤄보자.
4. Stationary 여부를 체크하는 통계적 방법 [ADF Test]
ADF TEST : 시계열의 정상성을 테스트하는 통계적 방법
1
2
3
4
5
6
7
8
9
10
11
12
| from statsmodels.tsa.stattools import adfuller
def augmented_dickey_fuller_test(timeseries):
# statsmodels 패키지에서 제공하는 adfuller 메서드를 호출합니다.
dftest = adfuller(timeseries, autolag='AIC')
# adfuller 메서드가 리턴한 결과를 정리하여 출력합니다.
print('Results of Dickey-Fuller Test:')
dfoutput = pd.Series(dftest[0:4], index=['Test Statistic','p-value','#Lags Used','Number of Observations Used'])
for key,value in dftest[4].items():
dfoutput['Critical Value (%s)' % key] = value
print(dfoutput)
|
1
| augmented_dickey_fuller_test(ts1)
|
1
2
3
4
5
6
7
8
9
| Results of Dickey-Fuller Test:
Test Statistic -4.444805
p-value 0.000247
#Lags Used 20.000000
Number of Observations Used 3629.000000
Critical Value (1%) -3.432153
Critical Value (5%) -2.862337
Critical Value (10%) -2.567194
dtype: float64
|
- ts1(Daily Minimum Temperatures in Melbourne)시계열이 안정적이지 않다는 귀무가설은 p-value가 거의 0에 가깝게 나타남.
- 따라서 이 귀무가설은 기각되고, 이 시계열은 안정적 시계열이라는 대립가설이 채택됨.
1
| augmented_dickey_fuller_test(ts2)
|
1
2
3
4
5
6
7
8
9
| Results of Dickey-Fuller Test:
Test Statistic 0.815369
p-value 0.991880
#Lags Used 13.000000
Number of Observations Used 130.000000
Critical Value (1%) -3.481682
Critical Value (5%) -2.884042
Critical Value (10%) -2.578770
dtype: float64
|
- ts2(International airline passengers) 시계열이 안정적이지 않다는 귀무가설은 p-value가 거의 1에 가깝게 나타남.
- p-value가 1에 가깝다는 것이 이 귀무가설(주어진 시계열 데이터가 안정적이지 않다.) 이 옳다는 직접적인 증거는 아니다.
- 하지만 이 귀무가설을 기각할 수는 없게 되었으므로 이 시계열이 안정적인 시계열이라고 말할 수는 없다.
5. Stationary하게 만들 방법
- 정성적인 분석을 통해 보다 정상성인 특징을 가지도록 기존의 시계열 데이터를 가공/변환
- 시계열 분해(Time series decomposition) 기법을 사용
5-1. 보다 Stationary한 시계열로 가공해 가기
5-1-1. 로그함수 변환
- 추이에 따라 분산이 점점 커지고 있음
- 시계열이 이런 특성을 보일 때는 로그함수로 변환을 하는 것이 도움이 됨.
1
2
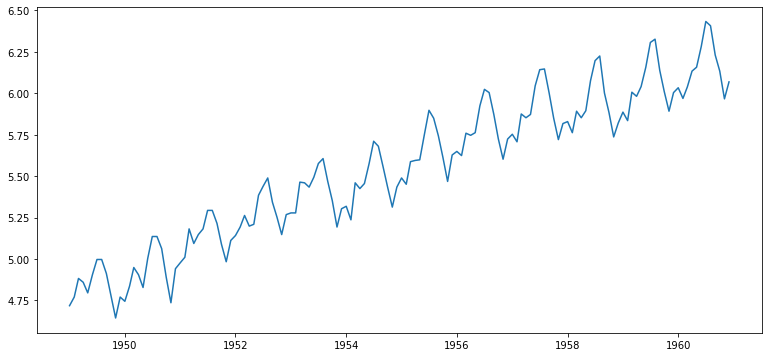
| ts_log = np.log(ts2)
plt.plot(ts_log)
|
1
| [<matplotlib.lines.Line2D at 0x7409d17398e0>]
|
로그 변환의 효과가 어떠했는지 따져 보기 위해 ADF Test를 수행해보자.
1
| augmented_dickey_fuller_test(ts_log)
|
1
2
3
4
5
6
7
8
9
| Results of Dickey-Fuller Test:
Test Statistic -1.717017
p-value 0.422367
#Lags Used 13.000000
Number of Observations Used 130.000000
Critical Value (1%) -3.481682
Critical Value (5%) -2.884042
Critical Value (10%) -2.578770
dtype: float64
|
- p-value가 0.42로 무려 절반 이상 줄어들었다.
- 정성적으로 시간 추이에 따른 분산이 일정해진다.
- 하지만 가장 두드러지는 문제점은 시간 추이에 따라 평균이 계속 증가하는 것이다.
5-1-2. Moving average 제거 - 추세(Trend) 상쇄
- 시계열 분석에서 위와 같이 시간 추이에 따라 나타나는 평균값 변화를 추세(trend)라고 한다.
- 이 변화량을 제거해주려면 거꾸로 oving Average, 즉 rolling mean을 구해서 ts_log에서 빼주자.
1
2
3
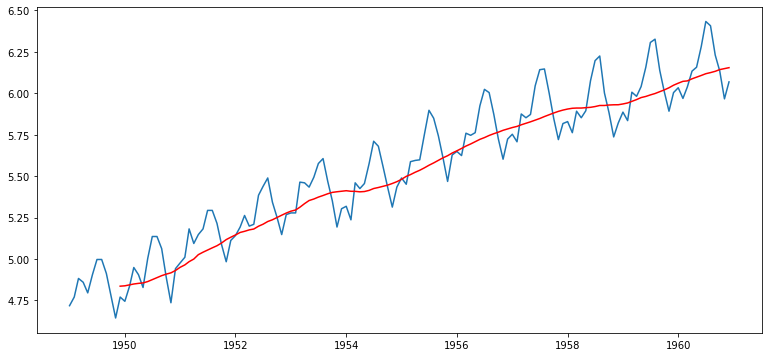
| moving_avg = ts_log.rolling(window=12).mean() # moving average구하기
plt.plot(ts_log)
plt.plot(moving_avg, color='red')
|
1
| [<matplotlib.lines.Line2D at 0x7409c5884ee0>]
|
1
2
| ts_log_moving_avg = ts_log - moving_avg # 변화량 제거
ts_log_moving_avg.head(15)
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
| Month
1949-01-01 NaN
1949-02-01 NaN
1949-03-01 NaN
1949-04-01 NaN
1949-05-01 NaN
1949-06-01 NaN
1949-07-01 NaN
1949-08-01 NaN
1949-09-01 NaN
1949-10-01 NaN
1949-11-01 NaN
1949-12-01 -0.065494
1950-01-01 -0.093449
1950-02-01 -0.007566
1950-03-01 0.099416
Name: Passengers, dtype: float64
|
- Moving Average 계산 시 (windows size=12인 경우) 앞의 11개의 데이터는 Moving Average가 계산되지 않으므로 ts_log_moving_avg에 결측치(NaN)가 발생
- 이 결측치들은 향후 Dicky-Fuller Test 시에 에러를 발생시킬 것이므로 이를 데이터셋에서 제거
1
2
| ts_log_moving_avg.dropna(inplace=True)
ts_log_moving_avg.head(15)
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
| Month
1949-12-01 -0.065494
1950-01-01 -0.093449
1950-02-01 -0.007566
1950-03-01 0.099416
1950-04-01 0.052142
1950-05-01 -0.027529
1950-06-01 0.139881
1950-07-01 0.260184
1950-08-01 0.248635
1950-09-01 0.162937
1950-10-01 -0.018578
1950-11-01 -0.180379
1950-12-01 0.010818
1951-01-01 0.026593
1951-02-01 0.045965
Name: Passengers, dtype: float64
|
이제 이전 스텝에서 정의했던 메서드들을 활용하여 ts_log_moving_avg를 정성, 정량적으로 분석해 보자.
1
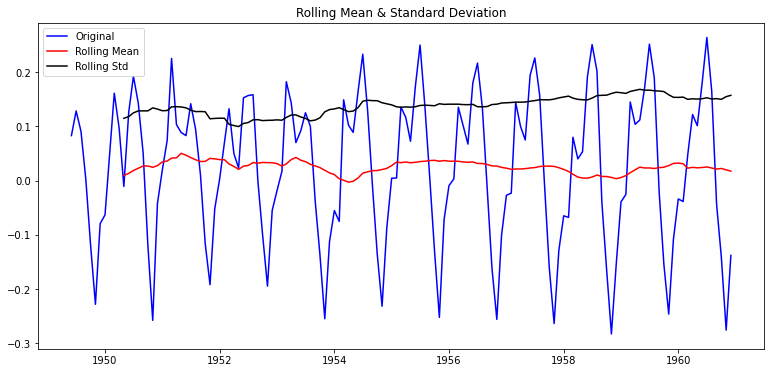
| plot_rolling_statistics(ts_log_moving_avg)
|
1
| augmented_dickey_fuller_test(ts_log_moving_avg)
|
1
2
3
4
5
6
7
8
9
| Results of Dickey-Fuller Test:
Test Statistic -3.162908
p-value 0.022235
#Lags Used 13.000000
Number of Observations Used 119.000000
Critical Value (1%) -3.486535
Critical Value (5%) -2.886151
Critical Value (10%) -2.579896
dtype: float64
|
- 드디어 p-value가 0.02 수준이 되었다.
- 95% 이상의 confidence로 이 time series는 stationary하다고 할 수 있다.
하지만 지금까지의 접근에서 한 가지 문제점이 있다. 바로 Moving Average를 계산하는 window=12로 정확하게 지정해 주어야 한다는 점이다.
만약 위 코드에서 window=6을 적용하면 어떤 결과가 나올까?
1
2
3
| moving_avg_6 = ts_log.rolling(window=6).mean()
ts_log_moving_avg_6 = ts_log - moving_avg_6
ts_log_moving_avg_6.dropna(inplace=True)
|
1
| plot_rolling_statistics(ts_log_moving_avg_6)
|
1
| augmented_dickey_fuller_test(ts_log_moving_avg_6)
|
1
2
3
4
5
6
7
8
9
| Results of Dickey-Fuller Test:
Test Statistic -2.273822
p-value 0.180550
#Lags Used 14.000000
Number of Observations Used 124.000000
Critical Value (1%) -3.484220
Critical Value (5%) -2.885145
Critical Value (10%) -2.579359
dtype: float64
|
그래프를 정성적으로 분석해서는 window=12일 때와 별 차이를 느낄 수 없지만 Augmented Dickey-Fuller Test의 결과 p-value는 0.18 수준이어서 아직도 안정적 시계열이라고 말할 수 없다.
이 데이터셋은 월 단위로 발생하는 시계열이므로 12개월 단위로 주기성이 있기 때문에 window=12가 적당하다는 것을 추측할 수도 있지만, moving average를 고려할 때는 rolling mean을 구하기 위한 window 크기를 결정하는 것이 매우 중요하다는 것을 기억해 두자!
이제 시간의 추이에 따라 평균이 증가하는 trend를 제거하였다. 그러나 여전히 안정적인 시계열이라고 하기에 걸리는 부분이 있다.
5-1-3. 차분(Differencing) - 계절성(Seasonality) 상쇄
- Trend에는 잡히지 않지만 시계열 데이터 안에 포함된 패턴이 파악되지 않은 주기적 변화는 예측에 방해가 되는 불안정성 요소이다.
- 이것은 Moving Average 제거로는 상쇄되지 않는 효과
- 이런 계절적, 주기적 패턴을 계절성(Seasonality)라고 함.
이런 패턴을 상쇄하기 위해 효과적인 방법에는 차분이 있다.
- 시계열을 한 스텝 앞으로 시프트한 시계열을 원래 시계열에서 빼주는 방법
- 남은 것은 현재 스텝 값 - 직접 스텝 값이 되어 이번 스텝에서 발생한 변화량을 의미하게 된다.
1
2
3
4
5
6
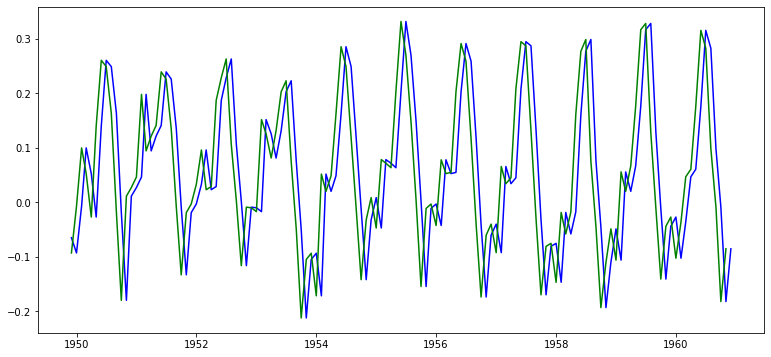
| # 시프트한 시계열과 원본 시계열에 대한 그래프를 그려보자
ts_log_moving_avg_shift = ts_log_moving_avg.shift(-1)
plt.plot(ts_log_moving_avg, color='blue')
plt.plot(ts_log_moving_avg_shift, color='green')
|
1
| [<matplotlib.lines.Line2D at 0x7409c57f6ac0>]
|
1
2
3
4
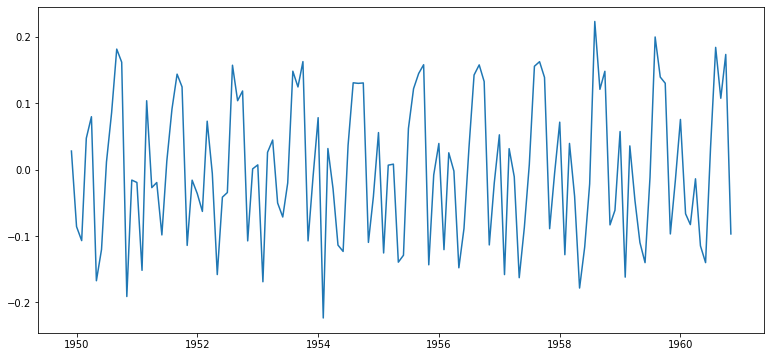
| # 원본 시계열에서 시프트한 시계열을 뺀 값을 그래프로 그려보자.
ts_log_moving_avg_diff = ts_log_moving_avg - ts_log_moving_avg_shift
ts_log_moving_avg_diff.dropna(inplace=True)
plt.plot(ts_log_moving_avg_diff)
|
1
| [<matplotlib.lines.Line2D at 0x7409c57b4e80>]
|
1
2
| # 이동평균과, 이동표준편차를 그래프에 나타내어 정성적으로 정상성 여부를 파악해보자.
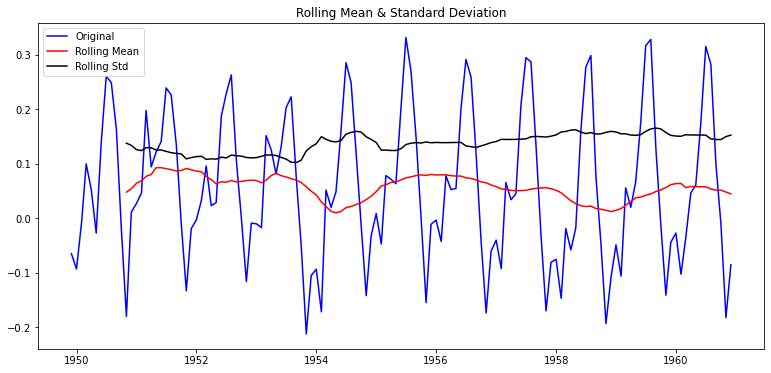
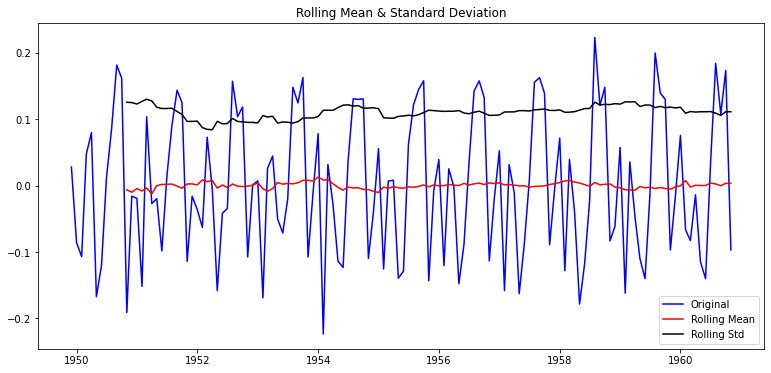
plot_rolling_statistics(ts_log_moving_avg_diff)
|
1
2
| # 차분의 효과가 어떠했는지 알아보기 위해 ADF Test를 수행하자.
augmented_dickey_fuller_test(ts_log_moving_avg_diff)
|
1
2
3
4
5
6
7
8
9
| Results of Dickey-Fuller Test:
Test Statistic -3.912981
p-value 0.001941
#Lags Used 13.000000
Number of Observations Used 118.000000
Critical Value (1%) -3.487022
Critical Value (5%) -2.886363
Critical Value (10%) -2.580009
dtype: float64
|
이동평균을 빼 주어 추세(Trend)를 제거하고 난 시계열에다가 1차 차분(1st order differencing)을 적용하여 Seasonality 효과를 다소 상쇄한 결과, p-value가 약 0.022 에서 0.0019로 1/10 정도로 줄어든 것을 볼 수 있다.
5-2. 시계열 분해(Time series decomposition)
- statsmodels 라이브러리 안에는 seasonal_decompose 메서드를 통해 시계열 안에 존재하는 trend, seasonality를 직접 분리해 낼 수 있는 기능이 있다.
- 이 기능을 활용하면 우리가 위에서 직접 수행했던 moving average 제거, differencing 등을 거치지 않고도 훨씬 안정적인 시계열을 분리해 낼 수 있게 된다.
이번에는 위에서 구했던 로그 변환 단계(ts_log)에서부터 출발해 보자.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
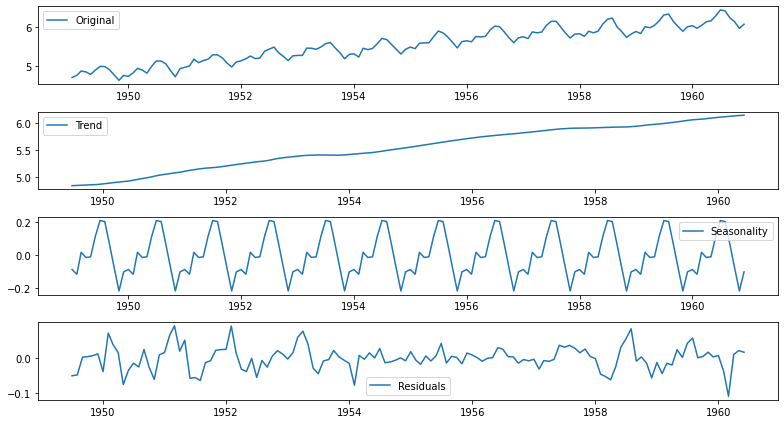
| from statsmodels.tsa.seasonal import seasonal_decompose
decomposition = seasonal_decompose(ts_log)
trend = decomposition.trend # 추세(시간 추이에 따라 나타나는 평균값 변화 )
seasonal = decomposition.seasonal # 계절성(패턴이 파악되지 않은 주기적 변화)
residual = decomposition.resid # 원본(로그변환한) - 추세 - 계절성
plt.rcParams["figure.figsize"] = (11,6)
plt.subplot(411)
plt.plot(ts_log, label='Original')
plt.legend(loc='best')
plt.subplot(412)
plt.plot(trend, label='Trend')
plt.legend(loc='best')
plt.subplot(413)
plt.plot(seasonal,label='Seasonality')
plt.legend(loc='best')
plt.subplot(414)
plt.plot(residual, label='Residuals')
plt.legend(loc='best')
plt.tight_layout()
|
Residual : Original 시계열에서 Trend와 Seasonality를 제거하고 난 나머지Trend + Seasonality + Residual = Original
1
2
3
| # Residual 에 대해 정상성 여부를 따져 보자.
plt.rcParams["figure.figsize"] = (13,6)
plot_rolling_statistics(residual)
|
1
2
| residual.dropna(inplace=True)
augmented_dickey_fuller_test(residual)
|
1
2
3
4
5
6
7
8
9
| Results of Dickey-Fuller Test:
Test Statistic -6.332387e+00
p-value 2.885059e-08
#Lags Used 9.000000e+00
Number of Observations Used 1.220000e+02
Critical Value (1%) -3.485122e+00
Critical Value (5%) -2.885538e+00
Critical Value (10%) -2.579569e+00
dtype: float64
|
Decomposing을 통해 얻어진 Residual은 압도적으로 낮은 p-value를 보여 줌.- 이 정도면 확실히 예측 가능한 수준의 안정적인 시계열이 얻어졌다고 볼 수 있다.
6. ARIMA 모델의 개념
앞에서 시계열 데이터가 Trend와 Seasonality, Residual로 분해되는 것을 확인했다. 또, Trend와 Seasonality를 잘 분리해 낸 경우 Residual이 예측력 있는 안정적인 시계열 데이터가 되는 것을 확인하였다.
ARIMA(Autoregressive Integrated Moving Average)를 사용하면 이 원리를 이용해 시계열 데이터 예측 모델을 자동으로 만들 수 있다.
ARIMA = AR(Autoregressive) + I(Integrated) + MA(Moving Average)
6-1. AR(자기회귀, Autoregressive)
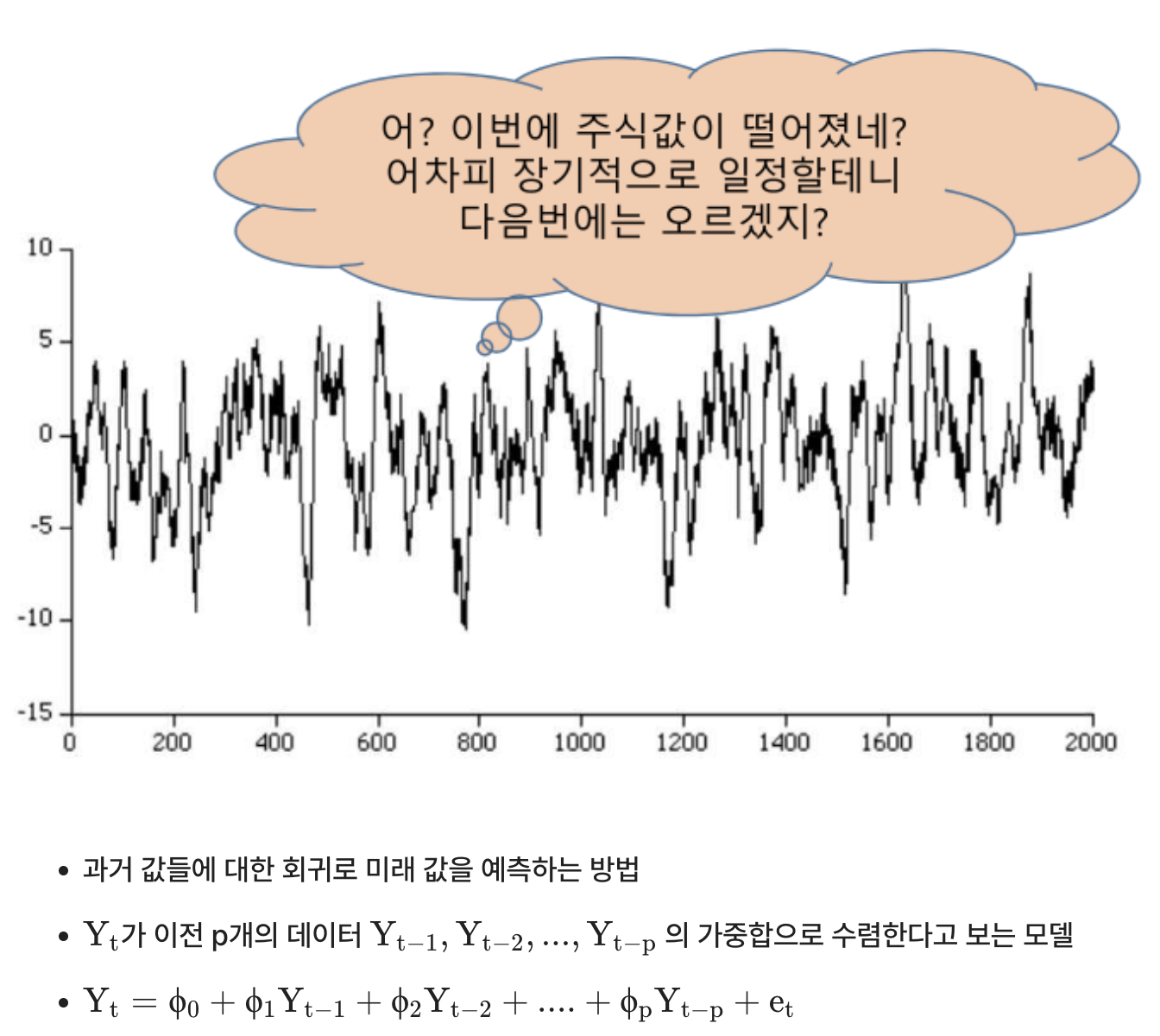
AR은 시계열의 Residual에 해당하는 부분을 모델링한다고 볼 수 있다.- 주식값이 항상 일정한 균형 수준을 유지할 것이라고 예측하는 관점이 바로 주식 시계열을
AR로 모델링하는 관점이라고 볼 수 있다.
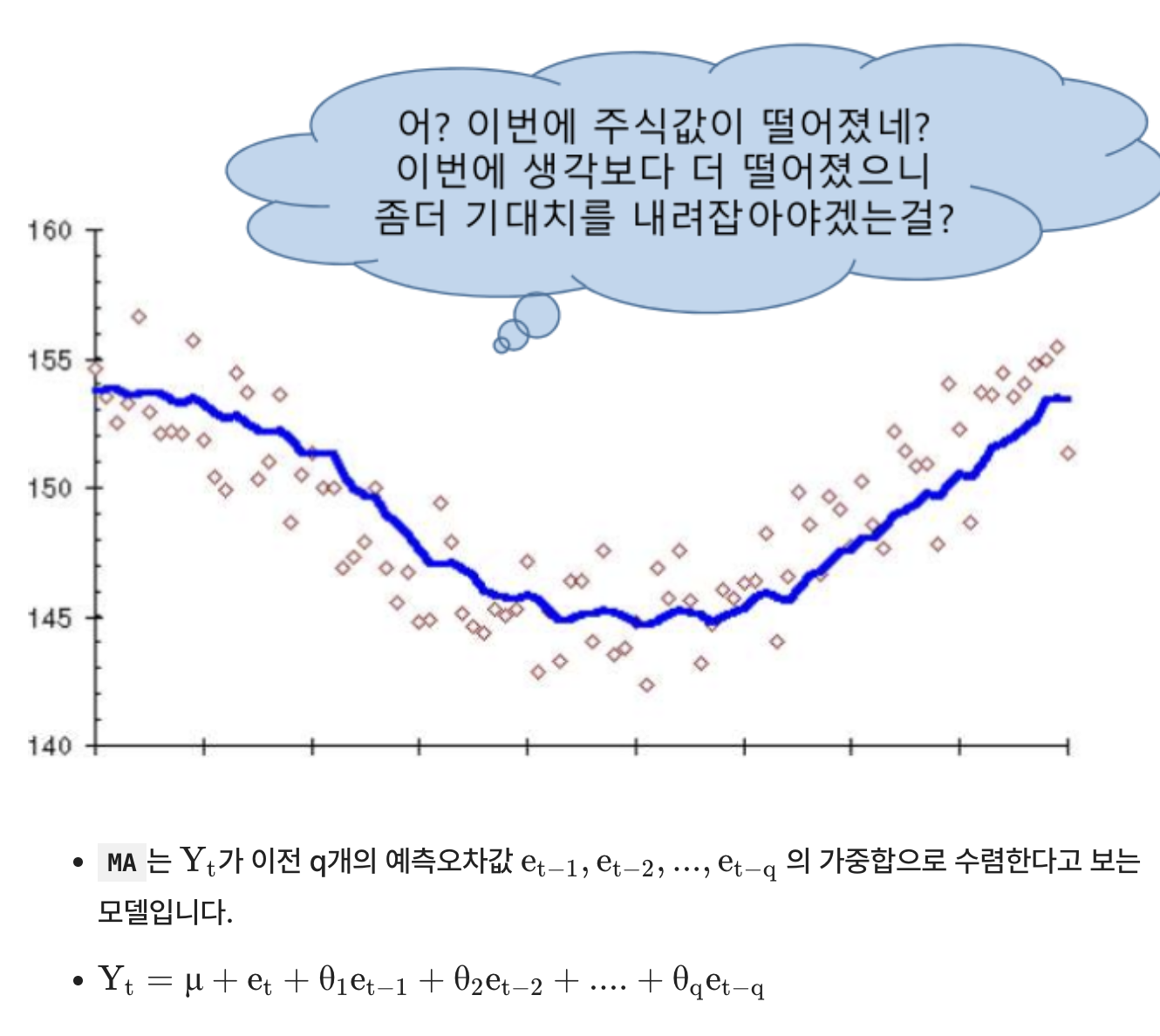
6-2. MA(이동평균, Moving Average)
- MA는 시계열의 Trend에 해당하는 부분을 모델링한다고 볼 수 있다.
- 주식값이 최근의 증감 패턴을 지속할 것이라고 보는 관점이 MA로 모델링하는 관점이라고 볼 수 있다.
6-3. I(차분 누적, Integration)
- 시점 t에서의 데이터 값이 이전 데이터와 d차 차분의 누적 합이라고 보는 모델
- I는 시계열의 Seasonality에 해당하는 부분을 모델링한다고 볼 수 있다.
6-4. ARIMA 모델의 모수 p, q, d
ARIMA의 모수는 아래의 3가지가 있다.
p : 자기회귀 모형(AR)의 시차d : 차분 누적(I) 횟수q : 이동평균 모형(MA)의 시차
이들 중 p 와 q 는 일반적으로 p + q < 2, p * q = 0 인 값을 사용한다. - p 나 q 중 하나는 0 - 이렇게 하는 이유는 많은 시계열 데이터가 AR이나 MA 중 하나의 경향만 가지기 때문
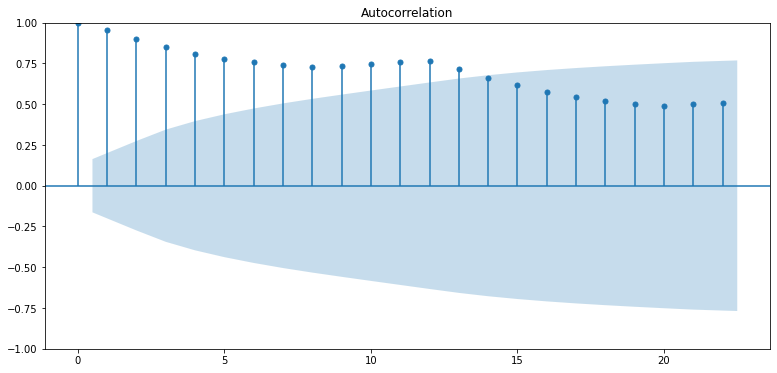
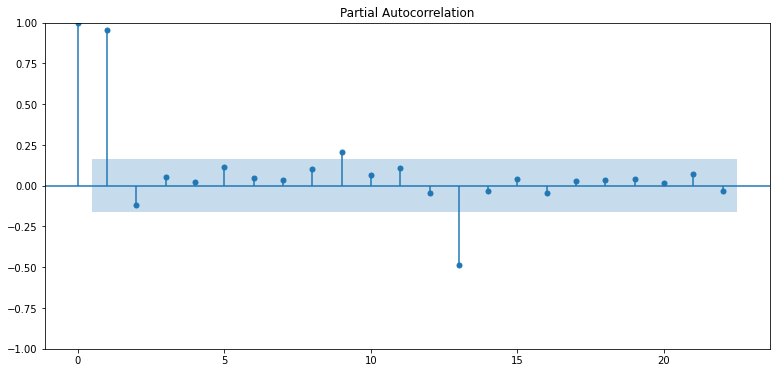
ACF(자기상관함수 - 과거의 값들과 얼마나 닮았는지), PACF(편자기상관함수 - 바로 직전의 과거의 값들과 얼마나 닮았는지)를 통해 파라미터를 결정해보자.
| 구분 | AR(p) | MA(q) |
|---|
| ACF | 점차적으로 감소 | 시차 q 이후에 0 |
| PACF | 시차 p 이후에 0 | 점차적으로 감소 |
1
2
3
4
5
| from statsmodels.graphics.tsaplots import plot_acf, plot_pacf
plot_acf(ts_log) # ACF : Autocorrelation 그래프 그리기
plot_pacf(ts_log) # PACF : Partial Autocorrelation 그래프 그리기
plt.show()
|
PACF
- p=1이 매우 적합
- p가 2 이상인 구간에서 PACF는 거의 0에 가까워지고 있음
- PACF가 0이라는 의미는 현재 데이터와 p 시점 떨어진 이전의 데이터는 상관도가 0
- 즉 아무 상관 없는 데이터이기 때문에 고려할 필요가 없다
ACF
- 점차적으로 감소하고 있어서
- AR(1) 모델에 유사한 형태
- q에 대해서는 적합한 값이 없어 보임.
- MA를 고려할 필요가 없다면 q=0으로 둘 수 있다.
d를 구하기 위해서는 좀 다른 접근이 필요하다. d차 차분을 구해 보고 이때 시계열이 안정된 상태인지를 확인해 보아야 함.
1
2
3
4
5
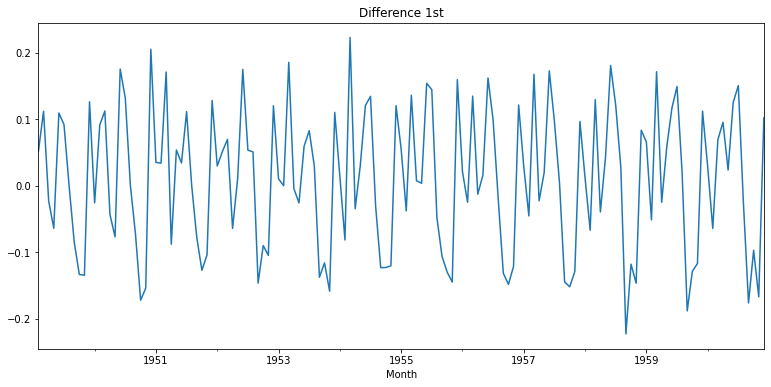
| # 1차 차분 구하기
diff_1 = ts_log.diff(periods=1).iloc[1:]
diff_1.plot(title='Difference 1st')
augmented_dickey_fuller_test(diff_1)
|
1
2
3
4
5
6
7
8
9
| Results of Dickey-Fuller Test:
Test Statistic -2.717131
p-value 0.071121
#Lags Used 14.000000
Number of Observations Used 128.000000
Critical Value (1%) -3.482501
Critical Value (5%) -2.884398
Critical Value (10%) -2.578960
dtype: float64
|
1
2
3
4
5
| # 2차 차분 구하기
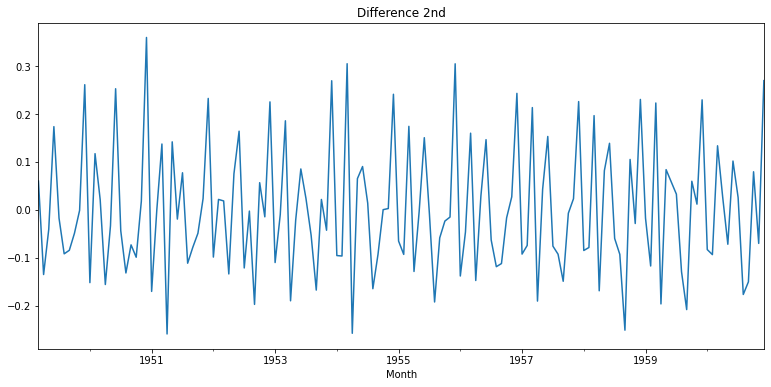
diff_2 = diff_1.diff(periods=1).iloc[1:]
diff_2.plot(title='Difference 2nd')
augmented_dickey_fuller_test(diff_2)
|
1
2
3
4
5
6
7
8
9
| Results of Dickey-Fuller Test:
Test Statistic -8.196629e+00
p-value 7.419305e-13
#Lags Used 1.300000e+01
Number of Observations Used 1.280000e+02
Critical Value (1%) -3.482501e+00
Critical Value (5%) -2.884398e+00
Critical Value (10%) -2.578960e+00
dtype: float64
|
- 1차 차분을 구했을 때 약간 애매한 수준의 안정화 상태를 보였다.
- 2차 차분을 구했을 때는 확실히 안정화 상태였지만, 이번 경우에는 d=1로 먼저 시도해 볼 수 있을 것 같다.
6-5. 학습 데이터 분리
1
2
3
4
5
6
7
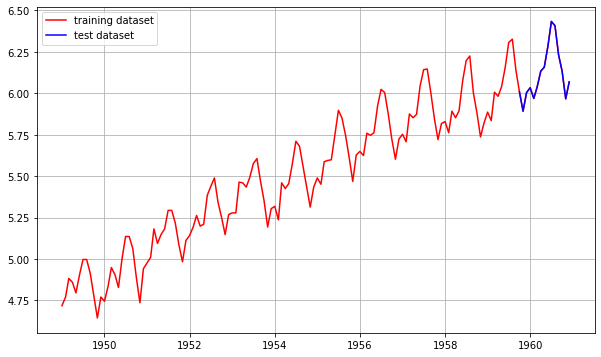
| train_data, test_data = ts_log[:int(len(ts_log)*0.9)], ts_log[int(len(ts_log)*0.9):]
plt.figure(figsize=(10,6))
plt.grid(True)
# train_data를 적용하면 그래프가 끊어져 보이므로 자연스러운 연출을 위해 ts_log를 선택
plt.plot(ts_log, c='r', label='training dataset')
plt.plot(test_data, c='b', label='test dataset')
plt.legend()
|
1
| <matplotlib.legend.Legend at 0x7409c5288040>
|
1
2
3
4
| # 데이터셋 형태 확인
print(ts_log[:2])
print(train_data.shape)
print(test_data.shape)
|
1
2
3
4
5
6
| Month
1949-01-01 4.718499
1949-02-01 4.770685
Name: Passengers, dtype: float64
(129,)
(15,)
|
7. ARIMA 모델 훈련과 추론
1
2
3
4
5
6
7
8
9
10
| import warnings
warnings.filterwarnings('ignore') #경고 무시
from statsmodels.tsa.arima.model import ARIMA
# Build Model
# 모수는 이전 그래프 + p=14로 진행하였다.
model = ARIMA(train_data, order=(14, 1, 0))
fitted_m = model.fit()
print(fitted_m.summary())
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
| SARIMAX Results
==============================================================================
Dep. Variable: Passengers No. Observations: 129
Model: ARIMA(14, 1, 0) Log Likelihood 219.935
Date: Tue, 27 May 2025 AIC -409.870
Time: 06:11:47 BIC -367.089
Sample: 01-01-1949 HQIC -392.488
- 09-01-1959
Covariance Type: opg
==============================================================================
coef std err z P>|z| [0.025 0.975]
------------------------------------------------------------------------------
ar.L1 -0.2709 0.082 -3.315 0.001 -0.431 -0.111
ar.L2 -0.0119 0.109 -0.110 0.913 -0.225 0.201
ar.L3 0.0018 0.046 0.040 0.968 -0.088 0.092
ar.L4 -0.0965 0.054 -1.778 0.075 -0.203 0.010
ar.L5 0.0406 0.050 0.808 0.419 -0.058 0.139
ar.L6 -0.0590 0.046 -1.282 0.200 -0.149 0.031
ar.L7 -0.0077 0.059 -0.132 0.895 -0.122 0.107
ar.L8 -0.1078 0.054 -1.998 0.046 -0.214 -0.002
ar.L9 0.0294 0.057 0.517 0.605 -0.082 0.141
ar.L10 -0.0721 0.056 -1.297 0.195 -0.181 0.037
ar.L11 0.0512 0.048 1.074 0.283 -0.042 0.145
ar.L12 0.8114 0.050 16.267 0.000 0.714 0.909
ar.L13 0.3296 0.104 3.176 0.001 0.126 0.533
ar.L14 -0.0713 0.128 -0.555 0.579 -0.323 0.180
sigma2 0.0016 0.000 7.318 0.000 0.001 0.002
===================================================================================
Ljung-Box (L1) (Q): 0.01 Jarque-Bera (JB): 2.57
Prob(Q): 0.92 Prob(JB): 0.28
Heteroskedasticity (H): 0.34 Skew: 0.30
Prob(H) (two-sided): 0.00 Kurtosis: 3.35
===================================================================================
Warnings:
[1] Covariance matrix calculated using the outer product of gradients (complex-step).
|
1
2
3
4
5
6
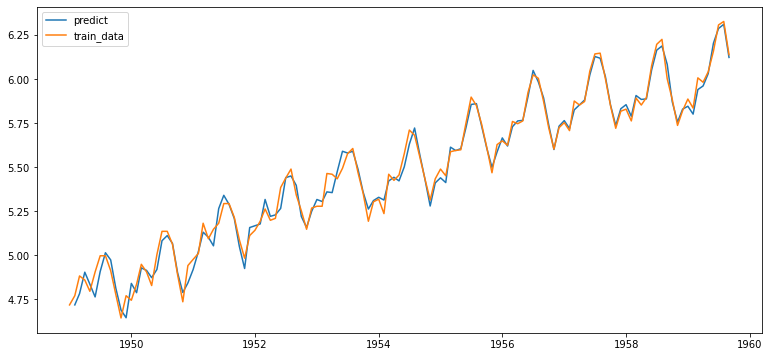
| # 훈련 결과를 시각적으로 확인해보자.
fitted_m = fitted_m.predict()
fitted_m = fitted_m.drop(fitted_m.index[0])
plt.plot(fitted_m, label='predict')
plt.plot(train_data, label='train_data')
plt.legend()
|
1
| <matplotlib.legend.Legend at 0x7409c1ab44c0>
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
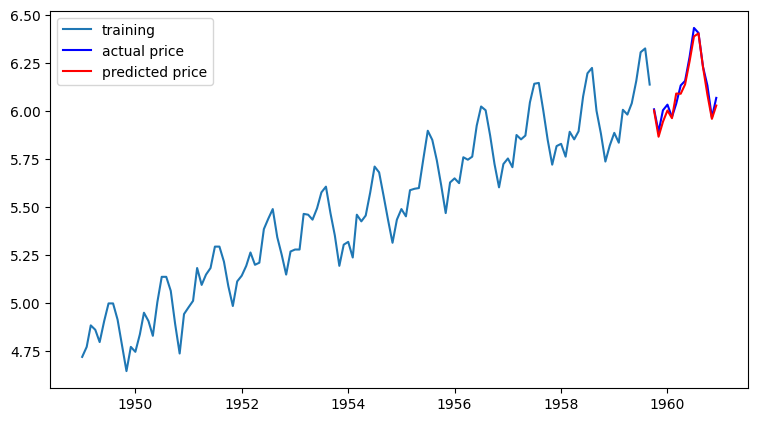
| # forecast() 메소드를 이용해 테스트 데이터 구간의 데이터를 예측해 보자.
model = ARIMA(train_data, order=(14, 1, 0)) # p값을 14으로 테스트
fitted_m = model.fit()
fc= fitted_m.forecast(len(test_data), alpha=0.05) # 95% conf
# Make as pandas series
fc_series = pd.Series(fc, index=test_data.index) # 예측결과
# Plot
plt.figure(figsize=(9,5), dpi=100)
plt.plot(train_data, label='training')
plt.plot(test_data, c='b', label='actual price')
plt.plot(fc_series, c='r',label='predicted price')
plt.legend()
plt.show()
|
시계열 데이터를 로그 변환하여 사용했으므로 다시 지수 변환해야 정확한 오차를 계산할 수 있다.
np.exp()를 통해 전부 원본 스케일로 돌린 후 MSE, MAE, RMSE, MAPE를 계산하자.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
| from sklearn.metrics import mean_squared_error, mean_absolute_error
import math
mse = mean_squared_error(np.exp(test_data), np.exp(fc))
print('MSE: ', mse)
mae = mean_absolute_error(np.exp(test_data), np.exp(fc))
print('MAE: ', mae)
rmse = math.sqrt(mean_squared_error(np.exp(test_data), np.exp(fc)))
print('RMSE: ', rmse)
mape = np.mean(np.abs(np.exp(fc) - np.exp(test_data))/np.abs(np.exp(test_data)))
print('MAPE: {:.2f}%'.format(mape*100))
|
1
2
3
4
| MSE: 226.73704637504432
MAE: 12.215491110579471
RMSE: 15.057790222175507
MAPE: 2.69%
|
- 최종적으로 예측 모델의 메트릭으로 활용하기에 적당한 MAPE 기준으로 2.69%을 보인다.
본 문서는 Aiffel LMS 강의 내용을 바탕으로 개인 학습 목적으로 정리하였습니다.
상업적 이용 목적은 없으며, 원 저작권은 Aiffel에 있습니다.