시계열이란? [정상성, KPSS Test, ADF Test, 로그 변환, 차분(diff)]
시계열이란? [정상성, KPSS Test, ADF Test, 로그 변환, 차분(diff)]
1. 시계열 데이터
- 시계열 데이터 : 일정 시간 간격으로 배치된 데이터들의 수열, 시간적으로 종속된 모든 데이터는 시계열에 해당함.
- 시계열 분석 : 시간 순서대로 정렬된 데이터에서 의미 있는 요약과 통계정보를 추출하기 위한 노력
2. 시계열의 성질
2-1. 시계열의 요소
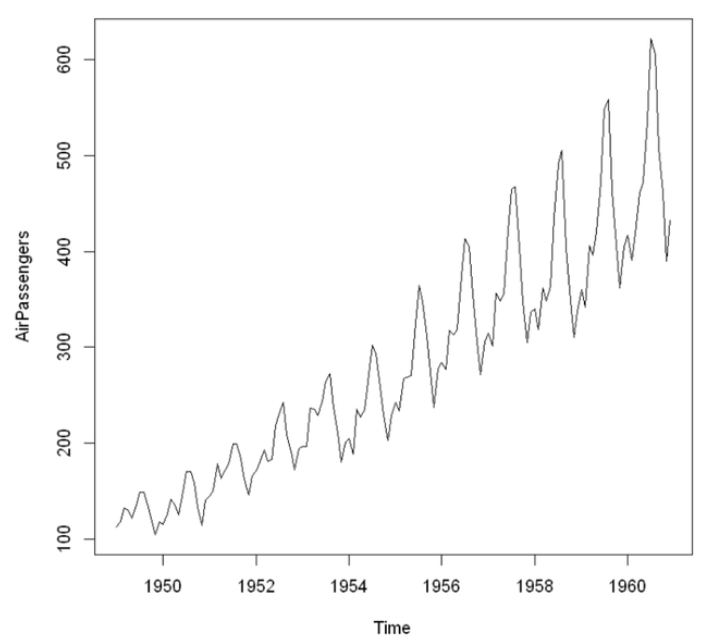
- 추세 (Trend)
- 장기적으로 증가하거나, 감소하는 경향성이 존재하는 것을 의미한다.
- 주로 시계열에서 기울기가 증가하거나, 감소할 때 관찰된다.
- 일정 기간 동안 지속되는 변화이며, 반복적인 패턴이 아니더라도 장기적인 방향성을 보여줌.
- 확정적 추세: 잘 변하지 않는 추세
- 확률적 추세: 계속 변하는 추세 (ex. 주식)
- 계절성 (Sesonality)
- 계절적 요인의 영향을 받아 1년, 혹은 일정 기간 안에 반복적으로 나타나는 패턴을 의미한다.
- 빈도의 형태로 나타나며 항상 일정한 경우가 많다.
- 주기성 (Cycle)
- 정해지지 않은 빈도, 기간으로 일어나는 상승 혹은 하락
- 학자마다 조금씩 정의가 다르니, 참고로만 알아두자.
- 정해지지 않은 빈도, 기간으로 일어나는 상승 혹은 하락
2-2. 요소별로 시계열 분해하기
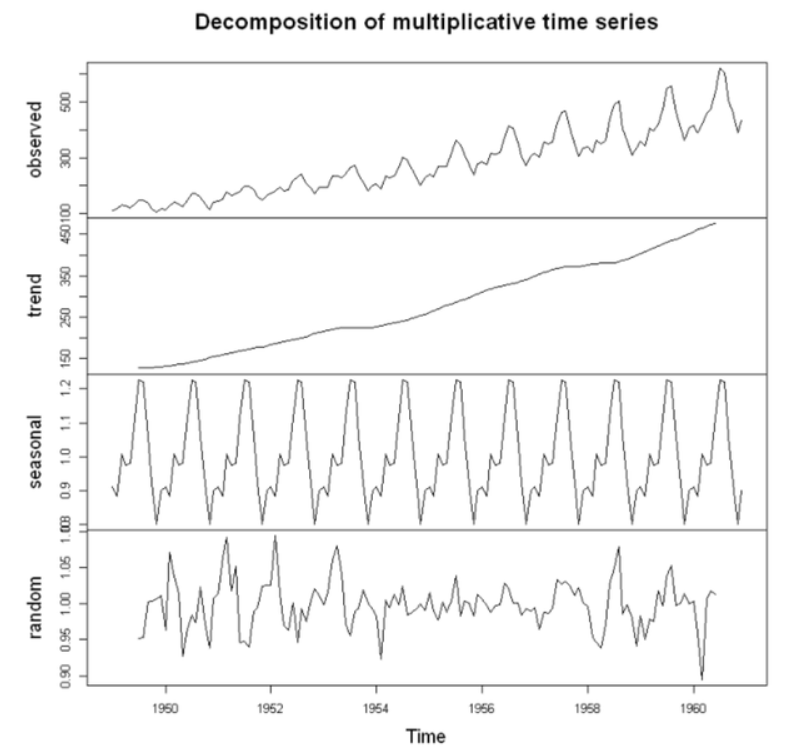
observed: 원래의 값(raw data)trend: 확정적 추세만을 뽑아서 시각화 한 것seasonal: 비슷한 모양이 구간별로 12번 반복 됨- 1년마다 반복되는 계절성을 나타내고 있음.
random: 잔차(residual), trend와 seasonal을 뺀 나머지를 나타냄.- 여기서는 더이상 뽑아낼 수 있는 시계열의 기본 성질이 없어야 한다.
2-3. 시계열의 정상성
정상성(Stationarity) : 시간이 지나도 데이터의 성질이 변하지 않는 것
- 평균이 일정하고,
- 분산이 일정하며,
- 시차(lag)에 따른 공분산이 일정하며,
- 계절성이나 추세가 없는 상태
정상 과정(Stationary Process) : 정상성을 띠는 확률 과정
정상성이 필요한 이유
- 과거 시점의 통계적인 특징을 통해 미래 시점에 적용하기 위해 시계열의 정상성(안정된 수준)을 알아야 함.
- 많은 시계열 분석 기법(AR, ARIMA 등)은 정상성을 전제로 하기 때문에, 비정상 시계열은 정상 시계열로 변환(차분 등) 후 분석해야 함.
3. 정상성이란?
- 정상성(Stationarity) : ‘시간에 상관없이 시계열이 일정한 성질’을 띠는 시계열을 지칭하는 것으로, ‘시간에 상관없이 일정한 것’을 의미한다.
- 비정상성(Non-Stationary) : 정상성과 반대로 시간의 흐름에 따라 통계적 특성이 변화하는 것
3-1. 정상성을 확인하는 방법
- KPSS(Kwiatkowski-Phillips-Schmidt-Shin Test) 검정
- ADF(Augmented Dickey-Fuller) 검정
3-1-1. KPSS 검정
KPSS검정(Kwiatkowski-Phillips-Schmidt-Shin Test) : 시계열이 평균이나 선형 추세(Linear Trend) 주변에 단위근으로 고정되어 있지 않은지 확인할 수 있음.
- 귀무가설 : 시계열 과정이 정상적이다.
- 대립가설 : 시계열 과정이 비정상적이다.
statsmodels라이브러리의kpss함수를 이용하여 쉽게 사용이 가능하다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
# Kpss 불러오기
from statsmodels.tsa.stattools import kpss
# 시계열 테스트 데이터
time_series_data_test = [1, 2, 3, 4, 5, 6, 7, 8, 9, 10]
# KPSS 검정 수행
kpss_outputs = kpss(time_series_data_test)
# 검정 결과 출력
print('KPSS test 결과 : ')
print('--'*15)
print('KPSS Statistic:', kpss_outputs[0])
print('p-value:', kpss_outputs[1])
1
2
3
4
KPSS test 결과 :
------------------------------
KPSS Statistic: 0.5941176470588235
p-value: 0.023171122994652404
유의수준α=0.05 (즉, 신뢰수준 95%)에서 p-value가 0.0231로 작기 때문에, 정상성에 대한 귀무가설을 기각하고 이 시계열은 비정상(non-stationary)이라고 판단함.
3-1-2. ADF 검정
ADF검정(Augmented Dickey-Fuller) : 시계열 데이터에서 단위근이 존재하는지의 여부를 찾는 검정 방법
- 귀무가설: 시계열의 단위근이 존재한다.
- 대립가설: 시계열이 정상성을 만족한다.
statsmodels라이브러리의adfuller함수를 이용한다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
# adfuller 불러오기
from statsmodels.tsa.stattools import adfuller
# 시계열 테스트 데이터
time_series_data_test = [1, 2, 3, 4, 5, 6, 7, 8, 9, 10]
# ADF 검정 수행
adf_outputs = adfuller(time_series_data_test)
# 검정 결과 출력
print('ADF Test 결과 : ')
print('--'*15)
print('ADF Statistic:', adf_outputs[0])
print('p-value:', adf_outputs[1])
1
2
3
4
5
6
7
8
ADF Test 결과 :
------------------------------
ADF Statistic: 0.0
p-value: 0.958532086060056
/opt/conda/lib/python3.9/site-packages/statsmodels/regression/linear_model.py:926: RuntimeWarning: divide by zero encountered in log
llf = -nobs2*np.log(2*np.pi) - nobs2*np.log(ssr / nobs) - nobs2
유의수준 α=0.05 (즉, 신뢰수준 95%)에서 p-value가 0.9585로 매우 크므로, 단위근 존재(비정상성)에 대한 귀무가설을 기각할 수 없다. 따라서 이 시계열은 비정상(non-stationary)으로 판단됨.
3-1-3. KPSS 검정과 ADF 검정의 차이
- 확정적 추세(Deterministic Trend)가 있는 경우
- KPSS는 기본 설정에서 평균 기준 정상성(around the mean)을 검정함
- 확정된 추세가 있으면 ADF와 상반된 결과가 나올 수 있음.
- KPSS는 기본 설정에서 평균 기준 정상성(around the mean)을 검정함
- ADF와 KPSS를 함께 사용하면 신뢰도가 높아짐.
- 반드시 시계열 그래프도 시각적으로 확인할 것!
3-2. 정상성을 부여하는 방법
3-2-1. 분산 일정
1. 로그 변환
1
2
3
4
5
6
7
8
9
import numpy as np
import matplotlib.pyplot as plt
import random
time_series_data = [1, 2, 3, 4, 5, 6, 7, 8, 9, 10]
# 로그 변환되지 않은 시계열 데이터 시각화
plt.plot(time_series_data)
plt.show()

1
2
3
4
5
6
7
import matplotlib.pyplot as plt
time_series_data_log = np.log(time_series_data)
# 로그 변환된 시계열 데이터 시각화
plt.plot(time_series_data_log)
plt.show()
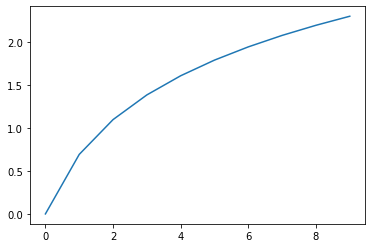
- 단순 선형이 로그 변환을 통해 비선형의 특징을 가지는 것을 알 수 있다.
3-2-2. 평균을 일정하게 만드는 방법
- 회귀(regression approach)
- 평활(smoothing)
- 차분(differencing)
1
2
3
4
5
6
7
8
9
10
11
12
13
import random
import pandas as pd
df0 = pd.DataFrame({'orig_value': [random.uniform(0, 100) for _ in range(100)]})
df1 = pd.DataFrame({'orig_value': [random.uniform(0, 100) for _ in range(100)]})
df0['smoothed_value'] = df0['orig_value'].rolling(5).mean()
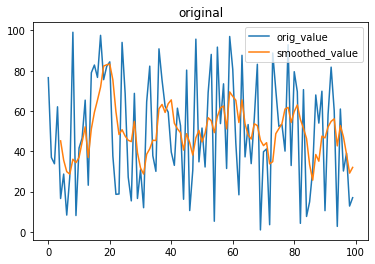
# 잡음이 포함된 시계열 데이터를 시각화
df0.plot(legend=True, title='original')
# 잡음이 제거된 시계열 데이터를 시각화
df0.plot(legend=True, subplots=True, title='smoothed')
1
array([<AxesSubplot:>, <AxesSubplot:>], dtype=object)
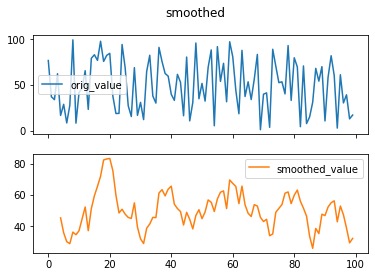
- ‘차분’이란 시계열 데이터들의 시간상의 차이를 구하는 것
- 한 번의 차이를 구하는 것을 ‘1차 차분’ 이라고 하며, 1차 차분값을 다시 차분하는 것을 ‘2차 차분’이라고 함.
- 차분은 데이터의 길이가 충분할 경우 여러 번 수행될 수도 있다.
- 하지만 대부분의 경우엔 1차 차분만으로 정상적인 시계열이 만들어지며, 2차 이상 차분을 할 경우 해당 데이터에 적합한 모델의 설명력이 낮아지며 데이터 소실이 커짐.
1
2
3
4
5
6
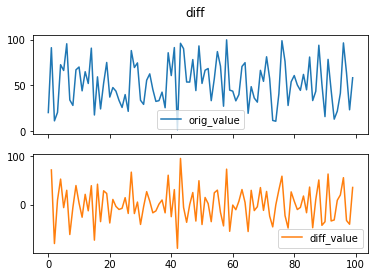
# 위에서 사용한 잡음이 있는 데이터를 그대로 활용하여 시각화
df1.plot(title='original')
# 차분을 적용하고 시각화
df1['diff_value'] = df1['orig_value'].diff()
df1.plot(legend=True, subplots=True, title='diff')
1
array([<AxesSubplot:>, <AxesSubplot:>], dtype=object)
본 문서는 Aiffel LMS 강의 내용을 바탕으로 개인 학습 목적으로 정리하였습니다.
상업적 이용 목적은 없으며, 원 저작권은 Aiffel에 있습니다.
많은 비정상적 시계열은 누적 과정(Integrated Process)이고, 정상적 시계열이 누적되어 비정상적 시계열을 이루기 때문에, 다시 누적된 것을 차분해줌으로써 그 이면의 정상적 과정을 우리가 볼 수 있게 되는 것!
This post is licensed under CC BY 4.0 by the author.