시계열 특징 및 분류 [tsfresh, Logistic Regression]
시계열 특징 및 분류 [tsfresh, Logistic Regression]
1. 시계열 데이터의 특징
1-1. 주요한 시계열 요약 통계 특징
- 평균과 분산
- 최댓값과 최솟값
- 시작과 마지막 값의 차이
- 국소적 최소와 최대의 개수
- 시계열의 평활 정도
- 평활 정도(Smoothness) : 무작위적 변화로 생기는 효과를 줄이는 방법 중 하나
- ex. 주어진 시계열 자료에 평균을 취하는 것은 가장 단순한 평활법
- 평활 정도(Smoothness) : 무작위적 변화로 생기는 효과를 줄이는 방법 중 하나
- 시계열의 주기성과 자기상관
- 시계열 주기성(Time series cycle) : 시계열이 증가하고 감소하는 패턴이 반복적으로 나타나지만, 그 빈도가 고정되지 않았을 때 시계열의 주기가 있다고 말함.
1-2. tsfresh
- 시계열의 feature를 자동으로 추출한다.
- 기술 통계학 지표, 비선형성과 복잡도 지표, 기록 압축 지표 등등 각종 지표를 자동으로 추출
- 논문에 따르면 63개의 시계열 특징 추출 방법론을 활용해 794개의 특징을 포착할 수 있다.
- 현재는 1200개 이상의 특징을 지원한다.
1
2
# 1. tsfresh 라이브러리 설치
!pip install tsfresh
1
2
3
# 2. 라이브러리 버전 충돌을 피하기 위해 런타임을 재시작합니다.
import os
os.kill(os.getpid(), 9)
1
2
3
# 3. robot execution 데이터셋 다운로드 및 불러오기
from tsfresh.examples.robot_execution_failures import download_robot_execution_failures, load_robot_execution_failures
download_robot_execution_failures()
- 불러온 데이터 확인
- timeseries : 데이터셋의 feature. (독립변수)
- y : True, False로 되어있는 binary classification (종속변수)
1
2
# 4. 불러온 데이터 확인
timeseries, y = load_robot_execution_failures()
1
timeseries
| id | time | F_x | F_y | F_z | T_x | T_y | T_z | |
|---|---|---|---|---|---|---|---|---|
| 0 | 1 | 0 | -1 | -1 | 63 | -3 | -1 | 0 |
| 1 | 1 | 1 | 0 | 0 | 62 | -3 | -1 | 0 |
| 2 | 1 | 2 | -1 | -1 | 61 | -3 | 0 | 0 |
| 3 | 1 | 3 | -1 | -1 | 63 | -2 | -1 | 0 |
| 4 | 1 | 4 | -1 | -1 | 63 | -3 | -1 | 0 |
| ... | ... | ... | ... | ... | ... | ... | ... | ... |
| 1315 | 88 | 10 | -10 | 2 | 39 | -21 | -24 | 5 |
| 1316 | 88 | 11 | -11 | 2 | 38 | -24 | -22 | 6 |
| 1317 | 88 | 12 | -12 | 3 | 23 | -24 | -24 | 5 |
| 1318 | 88 | 13 | -13 | 4 | 26 | -29 | -27 | 5 |
| 1319 | 88 | 14 | -13 | 2 | 15 | -25 | -25 | 6 |
1320 rows × 8 columns
1
y
1
2
3
4
5
6
7
8
9
10
11
12
1 True
2 True
3 True
4 True
5 True
...
84 False
85 False
86 False
87 False
88 False
Length: 88, dtype: bool
- 특징 추출(feature extraction)
- 그룹화 및 정렬 기준에 맞게 추출할 수 있다.
1
2
3
# 5. 특징 추출(feature extraction)
from tsfresh import extract_features
extracted_features = extract_features(timeseries, column_id="id", column_sort="time")
1
Feature Extraction: 100%|██████████| 528/528 [00:21<00:00, 24.03it/s]
1
extracted_features
| F_x__variance_larger_than_standard_deviation | F_x__has_duplicate_max | F_x__has_duplicate_min | F_x__has_duplicate | F_x__sum_values | F_x__abs_energy | F_x__mean_abs_change | F_x__mean_change | F_x__mean_second_derivative_central | F_x__median | ... | T_z__fourier_entropy__bins_5 | T_z__fourier_entropy__bins_10 | T_z__fourier_entropy__bins_100 | T_z__permutation_entropy__dimension_3__tau_1 | T_z__permutation_entropy__dimension_4__tau_1 | T_z__permutation_entropy__dimension_5__tau_1 | T_z__permutation_entropy__dimension_6__tau_1 | T_z__permutation_entropy__dimension_7__tau_1 | T_z__query_similarity_count__query_None__threshold_0.0 | T_z__mean_n_absolute_max__number_of_maxima_7 | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 1 | 0.0 | 0.0 | 1.0 | 1.0 | -14.0 | 14.0 | 0.142857 | 0.000000 | -0.038462 | -1.0 | ... | NaN | NaN | NaN | -0.000000 | -0.000000 | -0.000000 | -0.000000 | -0.000000 | NaN | 0.000000 |
| 2 | 0.0 | 1.0 | 1.0 | 1.0 | -13.0 | 25.0 | 1.000000 | 0.000000 | -0.038462 | -1.0 | ... | 1.073543 | 1.494175 | 2.079442 | 0.937156 | 1.234268 | 1.540306 | 1.748067 | 1.831020 | NaN | 0.571429 |
| 3 | 0.0 | 0.0 | 1.0 | 1.0 | -10.0 | 12.0 | 0.714286 | 0.000000 | -0.038462 | -1.0 | ... | 1.386294 | 1.732868 | 2.079442 | 1.265857 | 1.704551 | 2.019815 | 2.163956 | 2.197225 | NaN | 0.571429 |
| 4 | 0.0 | 1.0 | 1.0 | 1.0 | -6.0 | 16.0 | 1.214286 | -0.071429 | -0.038462 | 0.0 | ... | 1.073543 | 1.494175 | 2.079442 | 1.156988 | 1.907284 | 2.397895 | 2.302585 | 2.197225 | NaN | 1.000000 |
| 5 | 0.0 | 0.0 | 0.0 | 1.0 | -9.0 | 17.0 | 0.928571 | -0.071429 | 0.038462 | -1.0 | ... | 0.900256 | 1.320888 | 2.079442 | 1.156988 | 1.863680 | 2.271869 | 2.302585 | 2.197225 | NaN | 0.857143 |
| ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... |
| 84 | 1.0 | 1.0 | 0.0 | 1.0 | -1073.0 | 96833.0 | 7.142857 | -5.428571 | -0.038462 | -98.0 | ... | 0.735622 | 0.735622 | 1.386294 | 1.585771 | 2.253858 | 2.397895 | 2.302585 | 2.197225 | NaN | 24.285714 |
| 85 | 1.0 | 0.0 | 1.0 | 1.0 | 143.0 | 1683.0 | 1.357143 | 1.071429 | 0.076923 | 8.0 | ... | 0.735622 | 0.735622 | 1.667462 | 1.332245 | 1.589027 | 1.893788 | 2.163956 | 2.197225 | NaN | 5.571429 |
| 86 | 1.0 | 0.0 | 0.0 | 0.0 | 961.0 | 83497.0 | 9.071429 | 9.071429 | 0.807692 | 52.0 | ... | 0.735622 | 1.073543 | 1.732868 | 0.687092 | 0.983088 | 1.159589 | 1.227529 | 1.303092 | NaN | 9.285714 |
| 87 | 1.0 | 1.0 | 0.0 | 1.0 | 4509.0 | 1405437.0 | 12.928571 | 12.214286 | -1.038462 | 338.0 | ... | 0.735622 | 0.735622 | 1.386294 | 0.535961 | 0.836988 | 1.159589 | 1.497866 | 1.581094 | NaN | 40.285714 |
| 88 | 1.0 | 0.0 | 1.0 | 1.0 | -143.0 | 1427.0 | 0.785714 | -0.500000 | 0.038462 | -9.0 | ... | 1.255482 | 1.494175 | 2.079442 | 0.830518 | 1.242453 | 1.414279 | 1.609438 | 1.831020 | NaN | 5.428571 |
88 rows × 4698 columns
- impute
- 특징 추출된 모든 값을 동일한 열의 중앙/극단값으로 바꿉니다.
- -inf -> min
- +inf -> max
- NaN -> median
- select_features(X, y)
- 특징 행렬 X의 모든 특징(열)의 중요성을 확인하고 관련 특징만 포함하는 축소된 특징 행렬을 반환한다.(필터링)
1
2
3
4
5
6
7
8
from tsfresh import select_features
from tsfresh.utilities.dataframe_functions import impute
# 6. impute
impute(extracted_features)
# 7. select_features(X, y)
features_filtered = select_features(extracted_features, y)
1
2
# 8. 필터링된 값 확인
features_filtered
| F_x__value_count__value_-1 | F_x__abs_energy | F_x__root_mean_square | T_y__absolute_maximum | F_x__mean_n_absolute_max__number_of_maxima_7 | F_x__range_count__max_1__min_-1 | F_y__abs_energy | F_y__root_mean_square | F_y__mean_n_absolute_max__number_of_maxima_7 | T_y__variance | ... | T_x__change_quantiles__f_agg_"var"__isabs_True__qh_0.2__ql_0.0 | F_z__change_quantiles__f_agg_"mean"__isabs_True__qh_1.0__ql_0.8 | T_x__quantile__q_0.1 | F_y__has_duplicate_max | T_y__lempel_ziv_complexity__bins_3 | T_y__quantile__q_0.1 | F_z__time_reversal_asymmetry_statistic__lag_1 | F_x__quantile__q_0.2 | F_y__quantile__q_0.7 | T_x__change_quantiles__f_agg_"var"__isabs_False__qh_0.2__ql_0.0 | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 1 | 14.0 | 14.0 | 0.966092 | 1.0 | 1.000000 | 15.0 | 13.0 | 0.930949 | 1.000000 | 0.222222 | ... | 0.000000 | 0.0 | -3.0 | 1.0 | 0.400000 | -1.0 | -5.960000e+02 | -1.0 | -1.0 | 0.000000 |
| 2 | 7.0 | 25.0 | 1.290994 | 5.0 | 1.571429 | 13.0 | 76.0 | 2.250926 | 3.000000 | 4.222222 | ... | 0.000000 | 1.0 | -9.2 | 1.0 | 0.533333 | -3.6 | -6.803846e+02 | -1.0 | -1.0 | 0.000000 |
| 3 | 11.0 | 12.0 | 0.894427 | 5.0 | 1.000000 | 14.0 | 40.0 | 1.632993 | 2.142857 | 3.128889 | ... | 0.000000 | 3.0 | -6.6 | 0.0 | 0.533333 | -4.0 | -6.170000e+02 | -1.0 | 0.0 | 0.000000 |
| 4 | 5.0 | 16.0 | 1.032796 | 6.0 | 1.285714 | 10.0 | 60.0 | 2.000000 | 2.428571 | 7.128889 | ... | 0.000000 | 0.0 | -9.0 | 0.0 | 0.533333 | -4.6 | 3.426308e+03 | -1.0 | 1.0 | 0.000000 |
| 5 | 9.0 | 17.0 | 1.064581 | 5.0 | 1.285714 | 13.0 | 46.0 | 1.751190 | 2.285714 | 4.160000 | ... | 0.000000 | 0.0 | -9.6 | 0.0 | 0.466667 | -5.0 | -2.609000e+03 | -1.0 | 0.8 | 0.000000 |
| ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... |
| 84 | 0.0 | 96833.0 | 80.346334 | 167.0 | 105.285714 | 0.0 | 42780.0 | 53.404120 | 71.428571 | 1563.528889 | ... | 64.000000 | 46.0 | 203.2 | 0.0 | 0.533333 | 36.4 | -7.700628e+07 | -105.0 | 66.8 | 64.000000 |
| 85 | 0.0 | 1683.0 | 10.592450 | 14.0 | 13.714286 | 0.0 | 1523.0 | 10.076375 | 12.142857 | 14.755556 | ... | 4.666667 | 4.5 | -41.6 | 0.0 | 0.466667 | 1.0 | -1.050785e+04 | 5.8 | 10.6 | 13.555556 |
| 86 | 0.0 | 83497.0 | 74.608757 | 191.0 | 98.142857 | 0.0 | 21064.0 | 37.473546 | 47.714286 | 2788.595556 | ... | 0.250000 | 7.0 | -84.8 | 0.0 | 0.466667 | 19.6 | -5.544922e+06 | 30.4 | 38.4 | 0.250000 |
| 87 | 0.0 | 1405437.0 | 306.097697 | 471.0 | 340.000000 | 0.0 | 308658.0 | 143.447551 | 157.285714 | 6415.715556 | ... | 0.000000 | 90.5 | -139.2 | 0.0 | 0.466667 | 272.6 | -9.881845e+07 | 246.8 | 154.8 | 0.000000 |
| 88 | 0.0 | 1427.0 | 9.753632 | 27.0 | 11.428571 | 0.0 | 113.0 | 2.744692 | 3.428571 | 6.906667 | ... | 4.666667 | 0.0 | -24.6 | 0.0 | 0.533333 | -26.2 | -1.340477e+04 | -11.2 | 3.0 | 13.555556 |
88 rows × 671 columns
2. 시계열 데이터 분류
계열 데이터의 특징을 추출하고 시각화해보며, Logistic Regression을 사용하여 모델이 잘 학습(train)되었는지 score를 확인하자.
마지막으로 classification report를 통해 classification 평가지표를 만들어보자.
1
2
3
4
5
from tsfresh.examples.robot_execution_failures import download_robot_execution_failures, load_robot_execution_failures
download_robot_execution_failures()
timeseries, y = load_robot_execution_failures()
1
2
3
4
5
# 추가로 필요한 라이브러리 불러오기
import pandas as pd
import matplotlib.pyplot as plt
from sklearn.linear_model import LogisticRegression
from sklearn.metrics import classification_report
2-1. 데이터셋 가공
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
def custom_classification_split(x, y, test_size=0.3):
num_true = int(y.sum()*test_size) # int(21 * 0.3) = 6
num_false = int((len(y)-y.sum())*test_size) # int((88 - 21)*0.3) = 20
id_list = y[y==False].head(num_false).index.to_list() + y[y==True].head(num_true).index.to_list()
# y==False인것과 y==True인것의 인덱스값을 리스트로 변환하여 더해줍니다.
# y[y==False].head(num_false).index.to_list()는 19~38까지의 값이 리스트로
# y[y==True].head(num_true).index.to_list()는 1~6까지의 값이 리스트로
# id_list는 19~38 + 1~6이 더해진 리스트입니다.
y_train = y.drop(id_list) # y에서 id_list를 drop합니다.
y_test = y.iloc[id_list].sort_index() # 19~38, 1~6이 합쳐진 리스트를 정렬합니다.
X_train = x[~x['id'].isin(id_list)] # 대괄호 안에 있는 timeseries의 id와 id_list가 일치하는 것만 사용하고 물결표시는 안에 조건이 포함되어 있지 않는것만 사용하는 것입니다.
X_test = x[x['id'].isin(id_list)] # timeseries의 id와 id_list가 일치하는 것만 사용해서 timeseries에 적용
return X_train, y_train, X_test, y_test
1
2
3
4
5
6
7
8
9
# 커스텀한 함수를 적용한 데이터셋이 어떤 차이가 있는지 확인해봅시다.
X_train, y_train, X_test, y_test = custom_classification_split(timeseries, y)
print(X_train)
print('-'*50)
print(y_train)
print('-'*50)
print(X_test)
print('-'*50)
print(y_test)
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
id time F_x F_y F_z T_x T_y T_z
90 7 0 -3 1 53 -10 -4 0
91 7 1 0 -2 65 -4 -1 0
92 7 2 -1 -1 56 -7 -3 0
93 7 3 0 -2 60 -6 0 0
94 7 4 -1 -1 57 -7 -4 0
... .. ... ... ... ... ... ... ...
1315 88 10 -10 2 39 -21 -24 5
1316 88 11 -11 2 38 -24 -22 6
1317 88 12 -12 3 23 -24 -24 5
1318 88 13 -13 4 26 -29 -27 5
1319 88 14 -13 2 15 -25 -25 6
[930 rows x 8 columns]
--------------------------------------------------
7 True
8 True
9 True
10 True
11 True
...
84 False
85 False
86 False
87 False
88 False
Length: 62, dtype: bool
--------------------------------------------------
id time F_x F_y F_z T_x T_y T_z
0 1 0 -1 -1 63 -3 -1 0
1 1 1 0 0 62 -3 -1 0
2 1 2 -1 -1 61 -3 0 0
3 1 3 -1 -1 63 -2 -1 0
4 1 4 -1 -1 63 -3 -1 0
.. .. ... ... ... ... ... ... ...
565 38 10 -2 -1 58 -7 -6 -2
566 38 11 -4 0 60 -8 -9 -1
567 38 12 -3 0 59 -9 -6 -1
568 38 13 -1 1 61 -8 -4 -1
569 38 14 1 0 60 -8 -2 -1
[390 rows x 8 columns]
--------------------------------------------------
2 True
3 True
4 True
5 True
6 True
7 True
20 False
21 False
22 False
23 False
24 False
25 False
26 False
27 False
28 False
29 False
30 False
31 False
32 False
33 False
34 False
35 False
36 False
37 False
38 False
39 False
dtype: bool
2-2. 특징 추출하기
- MinimalFCParameters : feature를 최소(minimal)로 하여 계산을 수행합니다. 데이터셋 크기가 큰 경우 모든 feature를 계산하기 전에 설정을 minimal로 변경하여 빠르게 테스트하기 위해 사용합니다.
- train과 test 데이터셋을 minimal하게 계산한 값으로 변경해줍니다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
from tsfresh import extract_features
from tsfresh.feature_extraction import MinimalFCParameters
settings = MinimalFCParameters() # 계산 효율을 위해 minimal 셋팅
minimal_features_train = extract_features(
X_train,
column_id="id",
column_sort="time",
default_fc_parameters=settings # minimal 적용
)
minimal_features_test = extract_features(
X_test,
column_id="id",
column_sort="time",
default_fc_parameters=settings # minimal 적용
)
1
2
Feature Extraction: 100%|██████████| 372/372 [00:00<00:00, 2655.24it/s]
Feature Extraction: 100%|██████████| 156/156 [00:00<00:00, 2072.65it/s]
2-3. 추출된 특징 확인
1
minimal_features_train
| F_x__sum_values | F_x__median | F_x__mean | F_x__length | F_x__standard_deviation | F_x__variance | F_x__root_mean_square | F_x__maximum | F_x__absolute_maximum | F_x__minimum | ... | T_z__sum_values | T_z__median | T_z__mean | T_z__length | T_z__standard_deviation | T_z__variance | T_z__root_mean_square | T_z__maximum | T_z__absolute_maximum | T_z__minimum | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 7 | -13.0 | -1.0 | -0.866667 | 15.0 | 0.805536 | 0.648889 | 1.183216 | 0.0 | 3.0 | -3.0 | ... | -1.0 | 0.0 | -0.066667 | 15.0 | 0.442217 | 0.195556 | 0.447214 | 1.0 | 1.0 | -1.0 |
| 8 | -10.0 | -1.0 | -0.666667 | 15.0 | 1.135292 | 1.288889 | 1.316561 | 2.0 | 2.0 | -2.0 | ... | 0.0 | 0.0 | 0.000000 | 15.0 | 1.032796 | 1.066667 | 1.032796 | 3.0 | 3.0 | -1.0 |
| 9 | -10.0 | -1.0 | -0.666667 | 15.0 | 1.074968 | 1.155556 | 1.264911 | 2.0 | 3.0 | -3.0 | ... | 3.0 | 0.0 | 0.200000 | 15.0 | 1.045626 | 1.093333 | 1.064581 | 3.0 | 3.0 | -1.0 |
| 10 | -14.0 | -1.0 | -0.933333 | 15.0 | 0.249444 | 0.062222 | 0.966092 | 0.0 | 1.0 | -1.0 | ... | 0.0 | 0.0 | 0.000000 | 15.0 | 0.000000 | 0.000000 | 0.000000 | 0.0 | 0.0 | 0.0 |
| 11 | -13.0 | -1.0 | -0.866667 | 15.0 | 0.956847 | 0.915556 | 1.290994 | 1.0 | 3.0 | -3.0 | ... | -3.0 | 0.0 | -0.200000 | 15.0 | 0.400000 | 0.160000 | 0.447214 | 0.0 | 1.0 | -1.0 |
| ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... |
| 84 | -1073.0 | -98.0 | -71.533333 | 15.0 | 36.585729 | 1338.515556 | 80.346334 | -25.0 | 110.0 | -110.0 | ... | -232.0 | -21.0 | -15.466667 | 15.0 | 9.659998 | 93.315556 | 18.235497 | 0.0 | 28.0 | -28.0 |
| 85 | 143.0 | 8.0 | 9.533333 | 15.0 | 4.616877 | 21.315556 | 10.592450 | 19.0 | 19.0 | 4.0 | ... | -52.0 | -2.0 | -3.466667 | 15.0 | 2.156128 | 4.648889 | 4.082483 | 0.0 | 7.0 | -7.0 |
| 86 | 961.0 | 52.0 | 64.066667 | 15.0 | 38.235179 | 1461.928889 | 74.608757 | 148.0 | 148.0 | 21.0 | ... | -81.0 | -8.0 | -5.400000 | 15.0 | 5.462600 | 29.840000 | 7.681146 | 8.0 | 10.0 | -10.0 |
| 87 | 4509.0 | 338.0 | 300.600000 | 15.0 | 57.753268 | 3335.440000 | 306.097697 | 342.0 | 342.0 | 171.0 | ... | 475.0 | 35.0 | 31.666667 | 15.0 | 9.903983 | 98.088889 | 33.179311 | 44.0 | 44.0 | 13.0 |
| 88 | -143.0 | -9.0 | -9.533333 | 15.0 | 2.061283 | 4.248889 | 9.753632 | -6.0 | 13.0 | -13.0 | ... | 73.0 | 5.0 | 4.866667 | 15.0 | 0.884433 | 0.782222 | 4.946379 | 6.0 | 6.0 | 3.0 |
62 rows × 60 columns
1
minimal_features_train.columns
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
Index(['F_x__sum_values', 'F_x__median', 'F_x__mean', 'F_x__length',
'F_x__standard_deviation', 'F_x__variance', 'F_x__root_mean_square',
'F_x__maximum', 'F_x__absolute_maximum', 'F_x__minimum',
'F_y__sum_values', 'F_y__median', 'F_y__mean', 'F_y__length',
'F_y__standard_deviation', 'F_y__variance', 'F_y__root_mean_square',
'F_y__maximum', 'F_y__absolute_maximum', 'F_y__minimum',
'F_z__sum_values', 'F_z__median', 'F_z__mean', 'F_z__length',
'F_z__standard_deviation', 'F_z__variance', 'F_z__root_mean_square',
'F_z__maximum', 'F_z__absolute_maximum', 'F_z__minimum',
'T_x__sum_values', 'T_x__median', 'T_x__mean', 'T_x__length',
'T_x__standard_deviation', 'T_x__variance', 'T_x__root_mean_square',
'T_x__maximum', 'T_x__absolute_maximum', 'T_x__minimum',
'T_y__sum_values', 'T_y__median', 'T_y__mean', 'T_y__length',
'T_y__standard_deviation', 'T_y__variance', 'T_y__root_mean_square',
'T_y__maximum', 'T_y__absolute_maximum', 'T_y__minimum',
'T_z__sum_values', 'T_z__median', 'T_z__mean', 'T_z__length',
'T_z__standard_deviation', 'T_z__variance', 'T_z__root_mean_square',
'T_z__maximum', 'T_z__absolute_maximum', 'T_z__minimum'],
dtype='object')
2-4. 추출된 특징 시각화하기
1
2
plt.plot(minimal_features_train['F_x__sum_values'])
plt.show()
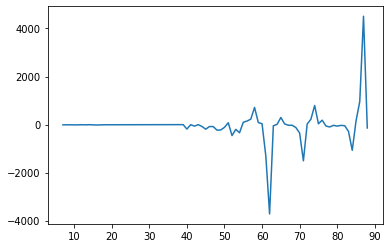
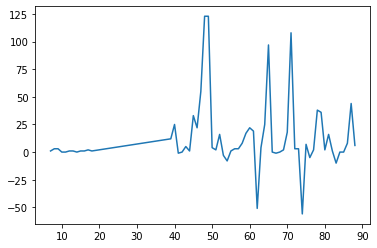
1
2
plt.plot(minimal_features_train['T_z__maximum'])
plt.show()
2-5. Logistic Regression 사용
- 회귀분석이라는 명칭과는 다르게 분류(Classification)를 할 때도 사용할 수 있다.
- 현재 사용중인 robot_execution_failures 데이터셋에서 y가 True와 False로 이루어져 있다.
- 이진 분류(binary classification) 문제이며 Logistic Regression을 사용할 수 있음.
- Logistic Regression은 어떤 범주에 속할 확률을 0(False)에서 1(True) 사이의 값으로 예측할 수 있다.
- x가 0.5보다 높거나 같은 경우 1, x가 0.5보다 낮은 경우는 0으로 분류함.
- 여기서 x는 독립변수인 feature라고 생각하시면 된다.
1
2
logistic = LogisticRegression()
logistic.fit(minimal_features_train, y_train)
1
LogisticRegression()
2-6. Logistic Regression score 확인
1
logistic.score(minimal_features_test, y_test)
1
0.6923076923076923
2-7. 분류 성능 평가 지표 확인
- Classification report는 scikit-learn에서 제공되는 기능
- 모델 혹은 알고리즘은 score로만 결과를 신뢰할 수 없다.
- 여기서 말하는 모델 혹은 알고리즘은 Logistic Regression
- 모델을 거쳐 나온 결과값(output)을 분석하여 이유가 있고 설명 가능한 상태가 되어야 함.
- 모델 혹은 알고리즘은 score로만 결과를 신뢰할 수 없다.
- Classification의 대표적인 검증 지표로 Precision, Recall, F1-score를 사용
- 아래의 지표를 해석해보면 이진 분류이므로 True와 False 각각 정밀도(Precision), 재현율(Recall), 조화평균(F1-score)의 값을 보여줌.
- 정확도(accuracy)는 score와 같다
- 매크로 평균(macro avg)은 평균의 평균.
- (각 클래스별 평균 / 클래스 = 매크로 평균)
- 여기서 클래스란 minimal_feature_train의 feature
- 특징 추출 후 나온 feature의 개수는 60개
- (각 클래스별 평균 / 클래스 = 매크로 평균)
- 가중 산술 평균(weighted avg)은 자료의 평균을 구할 때 자료 값의 중요도나 영향 정도에 해당하는 가중치를 반영하여 구한 평균값
1
2
3
# y는 True, False는 Target으로도 표현할 수 있습니다.
classification_report(y_test, logistic.predict(minimal_features_test), target_names=['true', 'false'], output_dict=True)
# y_test 내부에 있는 true, false와 일치
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
{'true': {'precision': 1.0,
'recall': 0.6,
'f1-score': 0.7499999999999999,
'support': 20},
'false': {'precision': 0.42857142857142855,
'recall': 1.0,
'f1-score': 0.6,
'support': 6},
'accuracy': 0.6923076923076923,
'macro avg': {'precision': 0.7142857142857143,
'recall': 0.8,
'f1-score': 0.6749999999999999,
'support': 26},
'weighted avg': {'precision': 0.868131868131868,
'recall': 0.6923076923076923,
'f1-score': 0.7153846153846153,
'support': 26}}
전체 정확도(Accuracy):69.2% — 전체 예측 중 약 69%가 정답.
클래스별 성능:
- true (총 20개 중)
- 정밀도(Precision): 1.00 → 예측이 맞으면 항상 정답!
- 재현율(Recall): 0.60 → 실제 true 중 60%만 맞춤
- F1-score: 0.75 → 정밀도와 재현율 균형 지표
false (총 6개 중)
- 정밀도: 0.43 → 예측이 자주 틀림
- 재현율: 1.00 → 실제 false는 모두 잘 맞춤.
- F1-score: 0.60
종합 요약:
- 모델은 true를 잘 예측하지만, false는 자주 헷갈림
- 정밀도는 높지만 재현율 불균형
+) 분류 모델 평가 지표 요약
| 지표 | 설명 |
|---|---|
| 정확도 (Accuracy) | 전체 중에서 맞춘 비율. 데이터가 불균형할 때는 신뢰하기 어려움. |
| 정밀도 (Precision) | 양성으로 예측한 것 중 실제로 양성인 비율. 거짓 양성 줄이는 데 중요. |
| 재현율 (Recall) | 실제 양성 중에서 양성으로 예측한 비율. 놓치는 양성 줄이는 데 중요. |
| F1-score | 정밀도와 재현율의 조화 평균. 불균형 데이터에서 성능 평가에 적합. |
본 문서는 Aiffel LMS 강의 내용을 바탕으로 개인 학습 목적으로 정리하였습니다.
상업적 이용 목적은 없으며, 원 저작권은 Aiffel에 있습니다.
This post is licensed under CC BY 4.0 by the author.